A 2-Person team serving model to 1.5 Million people with TrueFoundry
Read how we helped a 2 person MLE + DevOps team to scale up and serve their model to 1.5 Million+ people reliably and at much lower cloud costs using TrueFoundry

In the last few months, we have had the opportunity to work with a lean butted team. They have developed a state-of-the-art deep learning model and created partnerships to extremely talen ship it to more than 10 million users.
The last missing piece in their impact story was handling the engineering to accomplish this. The model was compute-heavy, and at the scale that they wanted to serve this model to its end users, they needed a reliable and performant infrastructure stack that the 2 of them could manage (1 DevOps Engineer and 1 ML Engineer).
Need for Async Deployment
The model was built to process audio inputs of varying sizes. Since the model had a high processing time (averaging ~5 seconds), it needed an async inference for each request to process and respond to these requests.
The team had developed a stack on AWS Sagemaker
The team has built its initial stack for serving the model on Sagemaker. However, when they conducted their first pilot using this design, they realized that serving the model reliably at its desired scale would be difficult with this stack.
Users faced lags of 8-10 Minutes
Even after using the Async setup, since the instances took time to scale up (8-10 mins per machine), the end-user experience was compromised when they had to bear this lag.
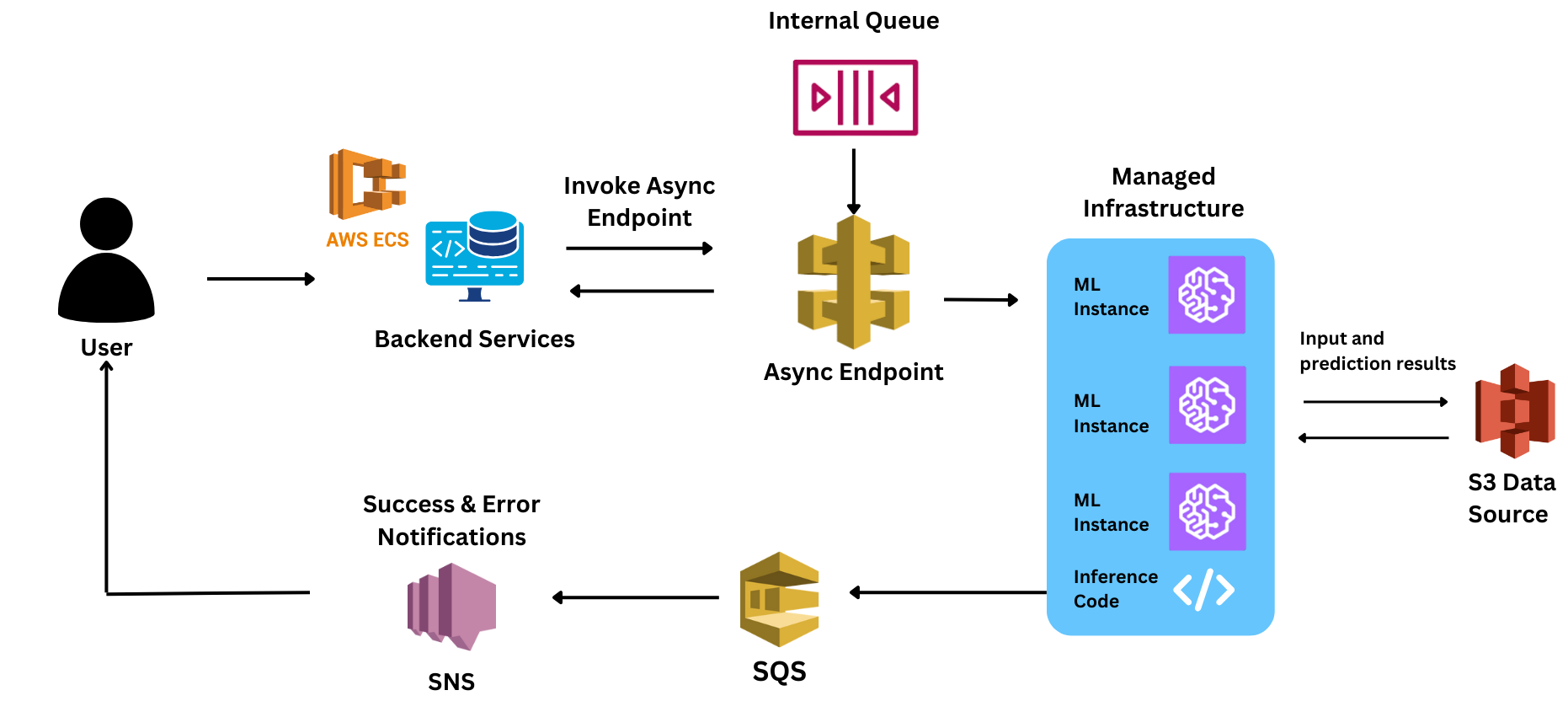
However, during the PoC, they faced huge lags in response times. Since they were new to many of the Sagemaker-related controls, they lost critical time finding the reason for the lags. Some of the challenges they faced were:
- Difficult to learn: They found it difficult as DS/MLEs to understand the new concepts required to use Sagemaker.
- Limited Visibility: Doing a root cause analysis of the issues, especially in production, was difficult due to unintuitive dashboards and interfaces.
- Difficult to scale: Scaling Sagamaker was slow, causing delays in user responses and a poor customer experience.
- Separate Quota: AWS requires you to make a separate case for getting capacity for Sagemaker-reserved GPU instances. The team found this process slow and restrictive.
- Expensive: Using GPUs with Sagemaker was expensive for the team because Sagemaker up marks such instances by 25-40% over raw EKS.
Post the PoC, the team lost confidence in Sagemaker and decided that they needed a solution that the two of them (One ML Engineer and 1 DevOps Engineer) could serve to their target audience of 10Mn+ users.
Deploying system on TrueFoundry in <2 Days
When we started engaging with the team, their pilot was ~7 Days away. We assured the team that we could assist them in migrating the entire stack and rebuilding it using TrueFoundry's modules in <2 Days so that they get ample time to test before their pilot had to go to production.
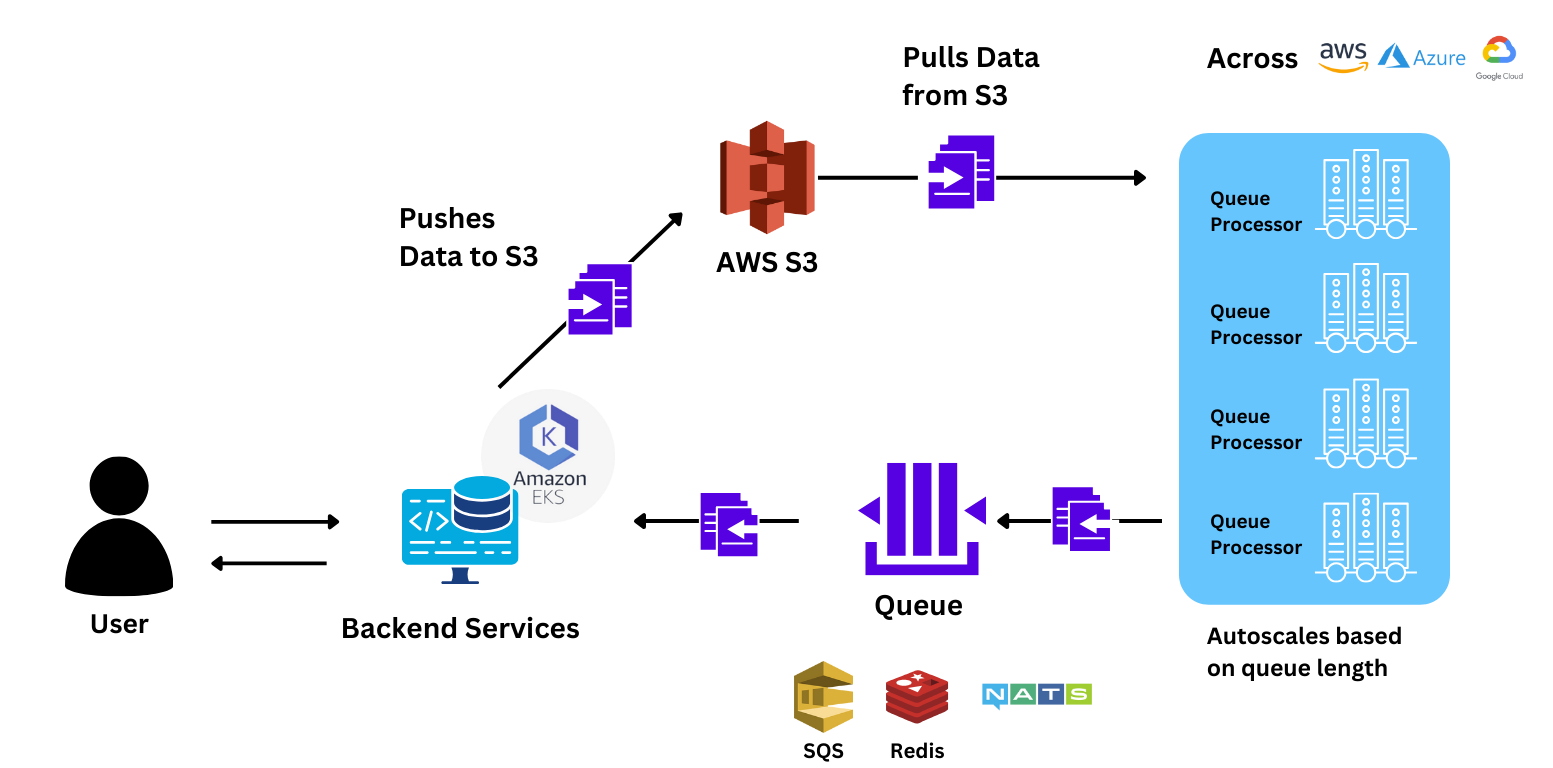
Much faster scaling
The team conducted benchmarks by sending a burst of 88 requests to the model to benchmark performance vs Sagemaker. TrueFoundry scaled up 78% faster than Sagemaker, giving the user much faster responses. The end-to-end time taken to respond to the query was 40% faster with TrueFoundry.
| Autoscaling Test Results (g5.xlarge, 2 Workers, 88 requests) | ||
|---|---|---|
| AWS Sagemaker | TrueFoundry | |
| Total Time to process 88 Requests | 660s | 395.9s |
| Autoscaling Test Results (g5.xlarge, 2 Workers, 88 requests) | ||
|---|---|---|
| AWS Sagemaker | TrueFoundry | |
| Time to scale up (1 worker to 2 worker) | 9 Mins | 2 Mins |
| Time before AutoScaler was triggered | 2 Min 30 s | 15 s |
Reliable scaling to 150+ Nodes
The team was simply able to scale the application to 150+ GPU nodes because:
- Easy to configure: They just had to change an argument on the UI and could easily configure autoscaling rules based on the backlog of incoming requests. This would otherwise have taken multiple back-and-forths with the engineering team.
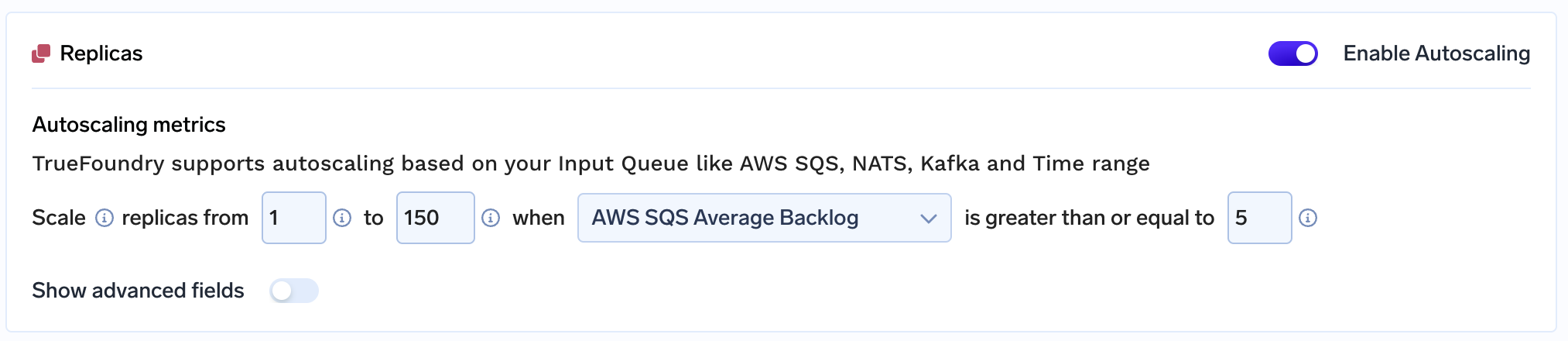
- Increased GPU Quota: With TrueFoundry, they could use both Spot and Raw ECS. Due to the GPU shortage with cloud providers, TrueFoundry also gave the team an option to scale across different GPU providers and regions.

- Spot Usage and Autoscaling: The team had to put in no additional effort to configure the use of spot instances for their services. Instances were also scaled down when traffic was low. Using TrueFoundry's reliability mechanism for spot usage and autoscaling settings, the team saved $100K+ dollars during the pilot period.
- Dev and Demo Environment: The team has also deployed a Dev and Demo service of the model to collect feedback while scaling down the machines when not in use.
1.5 Mn users already served and increasing by the Day!
Using TrueFoundry, the 2 member team can manage their entire workload, which often scales to more than 150 GPU nodes!! by themselves. While working with us, the most remarkable thing that stood out to the team was our customer support and low response times. TrueFoundry is invested in the success of its clients and hope that all our clients can scale and create impact at scales similar to this project!