Blazing Fast Docker Builds on Kubernetes for ML workloads

In the world of Machine Learning (ML), efficient Docker image building is not just a luxury—it's a necessity. Most companies have an existing Devops pipeline for building and pushing docker images either on local laptop or via CI/CD pipelines. However, as ML projects grow in complexity, with larger dependencies and more frequent iterations, the traditional Docker build process can become a significant bottleneck. This article highlights how we reduced the build time in Truefoundry by 5-15X compared to standard CI pipelines.
Why Fast Docker Builds Matter for ML
Large Dependencies
ML projects typically involve numerous heavy dependencies - Deep learning frameworks (PyTorch, TensorFlow), Scientific computing libraries (NumPy, SciPy), GPU drivers and CUDA toolkits. These dependencies can make Docker images several gigabytes in size, leading to lengthy build times.
Rapid Iteration Cycles
ML development involves frequent code changes that need to be deployed in order to test them. Datascientists often don't have the hardware required to run their code on their local laptops - which means the code needs to run on the remote cluster which will often involve building images.
- Frequent code changes for model improvements
- Regular updates to dependencies
- Continuous experimentation with different model architectures- A/B testing with various configurations
At Truefoundry, our goal is to enable developers to move at a rapid iteration pace and for that we wanted to make our docker builds really fast. To understand what we did to optimize the build times, let's first understand how we used to build images earlier on Truefoundry.
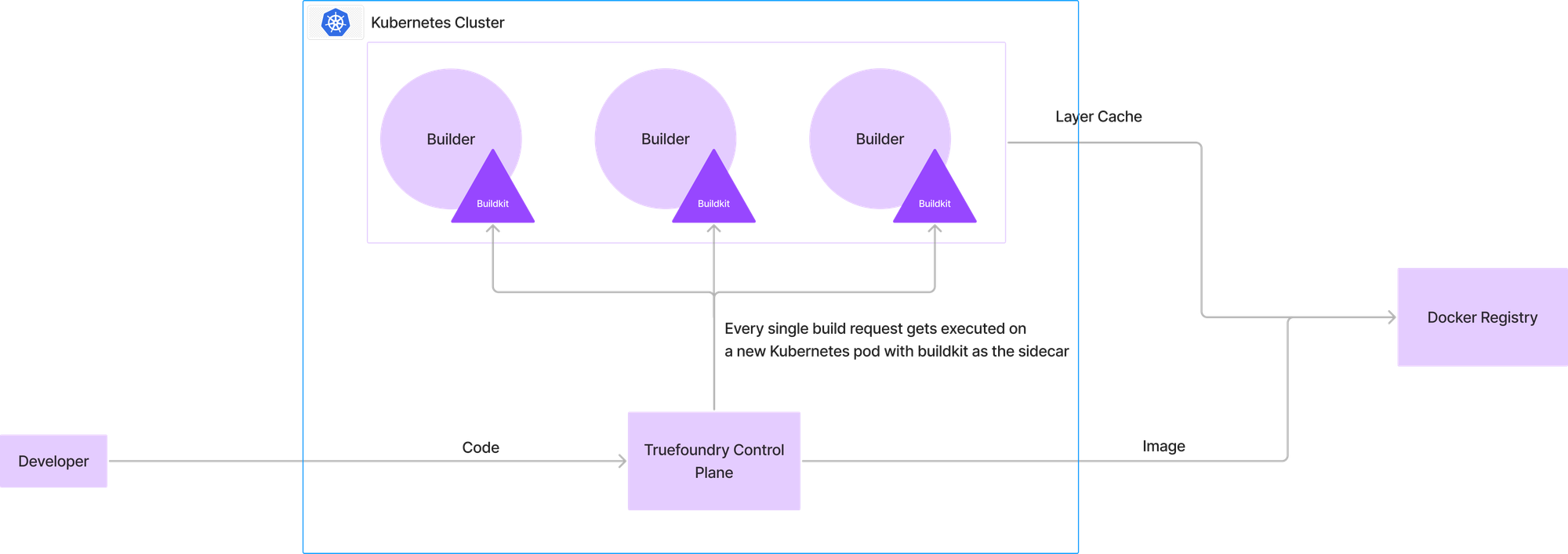
Everytime a developer would want to build an image, the code was uploaded to the control plane, wherein a new pod would start building the image with buildkit running in the sidecar. The destination docker registry would serve as the caching layer and the final image will be pushed to the docker registry.
This setup is identical to most CI builders and follows the same pros and cons as current CI setups
This had the following advantages:
- Any number of parallel builds can be supported at a time since the system can scale infinitely and all builds run as individual pods.
- Buildkit of every single build would be isolated - hence not affecting other builds.
- Buildkit provides state of the art parallel processing and advanced caching functionalities.
However, there were a few disadvantages of this approach:
1. The buildkit pod requires a large number of resources which leads to a high startup time for the build runner.
2. It takes a lot of time to download the cache from the docker registry leading to slow build times.
3. There is no reuse of the cache across builds of different workloads.
We wanted to provide the same (and perhaps better) experience of building images remotely compared to local builds
Making the docker image building process fast
We decided to first host the buildkit pod as a service on Kubernetes that can be shared among multiple builders and can provide local disk caching so that docker builds can be really fast.
However, there are a few constraints with this approach:
1. Buildkit has a fundamental constraint that the cache filesystem can only be used by one instance of Buildkit. What this means if we run multiple instance of the buildkit for processing multiple builds in parallel, each of them will have their own cache and that cannot be shared.
2. If we run multiple instances of buildkit with each having its own cache, the same workload should be routed to the same machine so that the cache can be used effectively. This requires a custom routing logic.
3. Auto scaling of the buildkit pods based on the number of builds running is non-trivial. We cannot use CPU usage of the buildkit pods as an autoscaling metric since its possible Kubernetes terminates a running small build assuming nothing is running on that machine.
Having a dynamic number of buildkit pods with the workloads being routed to the same instance of cache is a non-trivial problem. Attaching and removing volumes across pods is quite slow in Kubernetes which leads to very high times for the builds to start.
To overcome the above constrains, we came up with a hybrid approach such that most of the builds get completed really fast while in some rare cases of high concurrency of parallel builds, we resort to our earlier flow of running buildkit in a sidecar. In the architecture thats described in the picture below, we configure a certain build concurrency below which all builds will go to the buildkit service. To illustrate this, lets consider that we allot one machine with 4 CPU and 16GB RAM for the buildkit service. From historical build data, we can figure out that this machine can sustain 2 concurrent builds. So if there is one build already running and a new one comes through, its routed to the buildkit service. However, if one more build comes in, we will route it to the earlier model which uses the layer cache stored in the docker registry and runs buildkit as a sidecar.
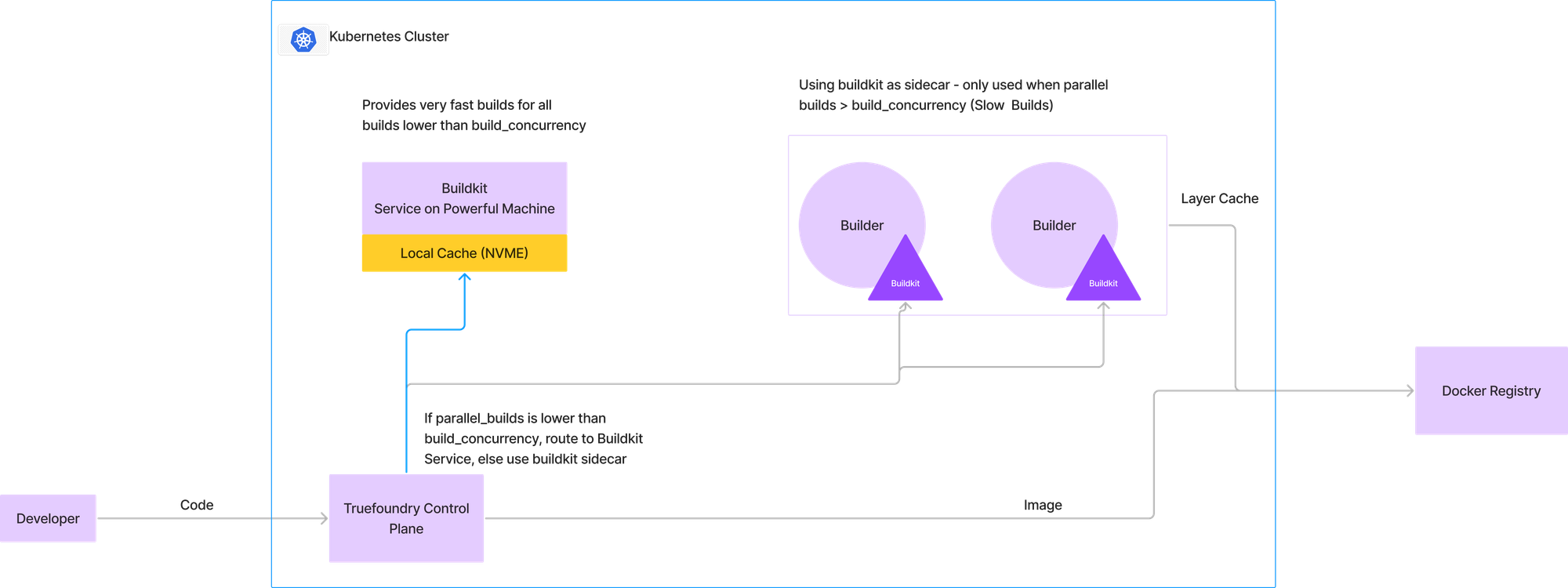
This enables us to provide ultra-fast builds for 99% of the workloads whereas in a very few cases, the build ends up taking the time that it usually takes in standard CI pipelines.
Further Improvements in Build Speed
There are a few other improvements we did in the build process to make it faster. A few of them are:
- Replacing pip with uv: uv allows much faster dependency resolution and package installation for Python compared to pip. Replacing pip with uv gave us around a 40% reduction in the build time.
- Using NVME disk instead of EBS: NVME disks provide fast read and write access which helps in build speed improvements by making cache writes and reads faster.
Benchmarking the speed improvements
To benchmark our experiments, we took one sample Dockerfile which represents the most common scenario for ML workloads.
FROM tfy.jfrog.io/tfy-mirror/python:3.10.2-slim
WORKDIR /app
RUN echo "Starting the build"
COPY ./requirements.txt /app/requirements.txt
RUN pip install -r requirements.txt
COPY . /app/
EXPOSE 8000
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]The requirements.txt is as follows:
fastapi[standard]==0.109.1
huggingface-hub==0.24.6
vllm==0.5.4
transformers==4.43.3We benchmarked the build for 3 scenarios:
- First Time build (No cache)
- Second Time Build After changing python code, but no change in dependencies.
- Second Time Build after changing dependencies in requirements.txt.
The timings include the time to both build and push the image to the registry and the unit is in seconds.
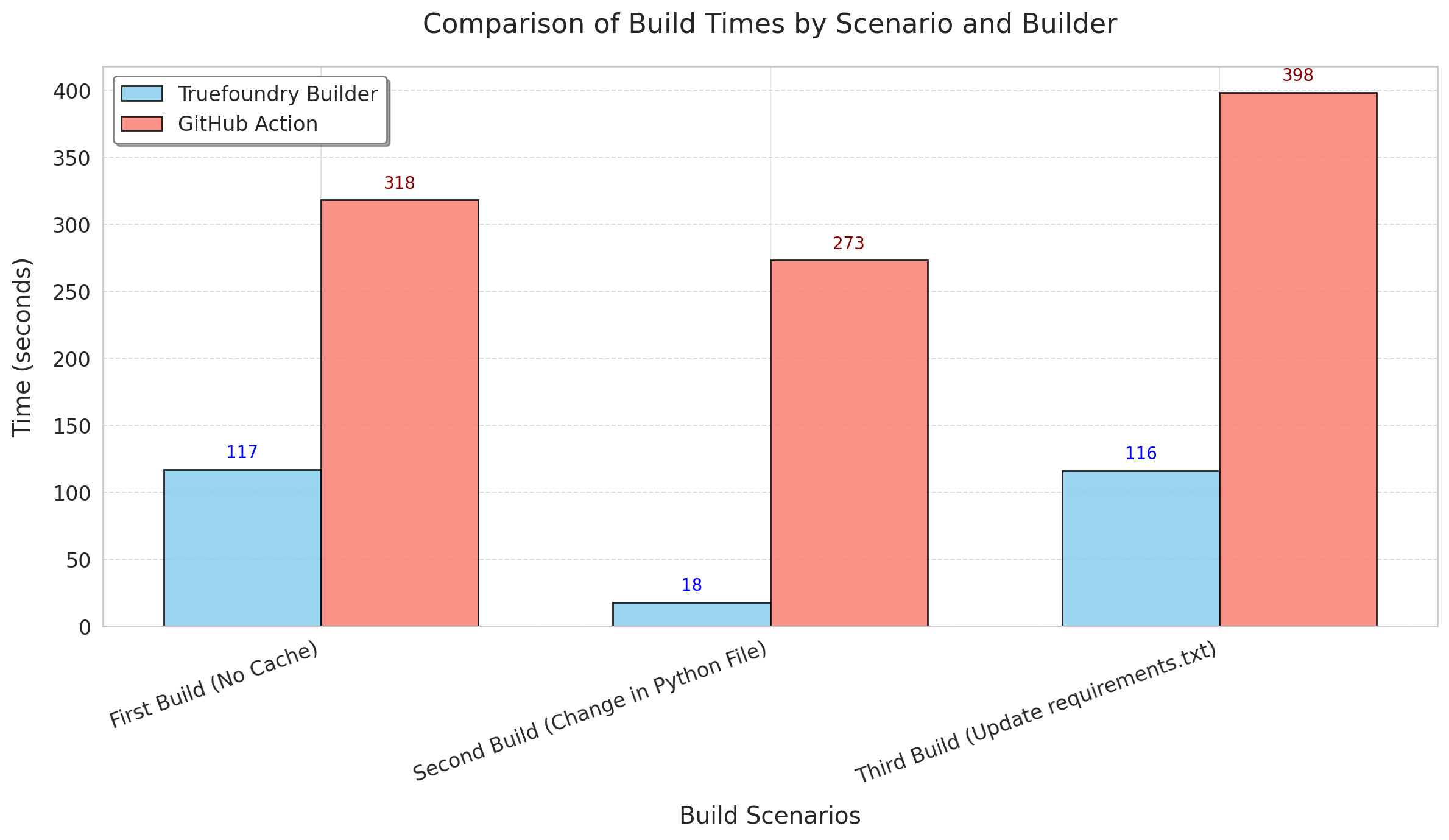
The second scenario is the most common scenario encounterd by developers and as we can see its almost a 15X improvement in the build times.
We also benchmarked a scenario with a dockerfile containing triton as the base image, which is a much larger base image.
FROM nvcr.io/nvidia/tritonserver:24.09-py3
WORKDIR /app
RUN echo "Starting the build"
COPY ./requirements2.txt /app/requirements.txt
RUN pip install -r requirements.txt
RUN echo "Finished the build"The results are the following:
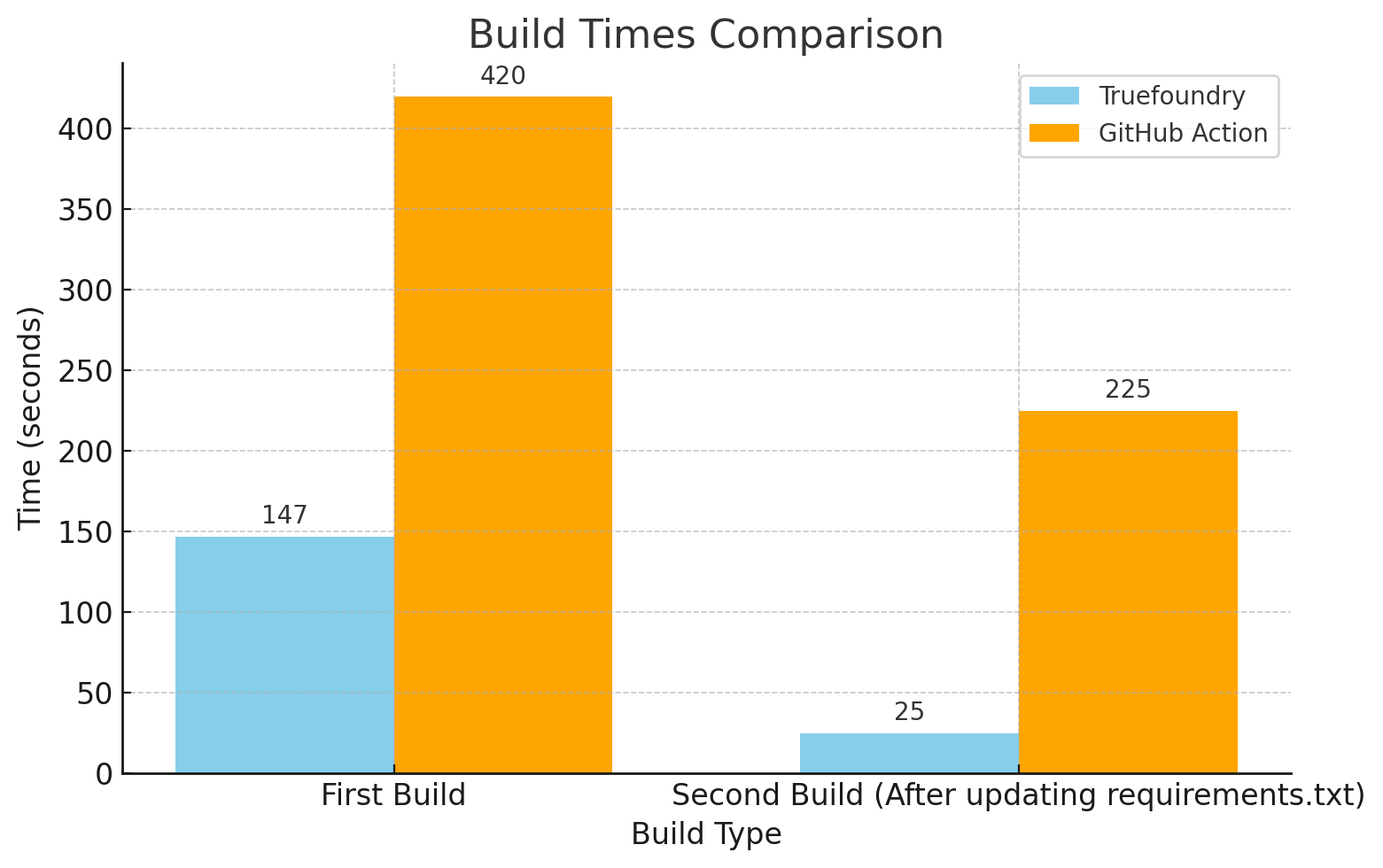
The above change has massively improved the experience of developers using the Truefoundry platform and allows to iterate really fast with their development process as well as save infrastructure code.