Cluster Autoscaling for Big 3 Clouds ☁️
It won’t be wrong to say that every business needs to handle more traffic, process more data, and support more customers as they grow. They often need to scale their infrastructure to keep up with the increasing demands. This is also true if your business has seasonality. Imagine an e-commerce website that sees a lot of traffic over the holidays, such as on Black Friday or Cyber Monday. The website's traffic may grow dramatically during these busy times. The website may have delayed page load problems and irritate users if it cannot handle the increased demand. As a result, the company may experience lost sales and a deterioration in its reputation.
One way to address this issue is by manually increasing the number of servers in the infrastructure to handle the increased traffic. However, manually scaling up and down can be time-consuming, error-prone, and difficult to manage. This is where cluster autoscaling comes in. Cluster autoscaling automatically adjusts the number of servers in the infrastructure based on certain conditions, such as CPU usage, memory usage, or incoming requests. This means the infrastructure can scale up or down based on the current demand without manual intervention.
This blog post will explore what cluster autoscaling is, why it is needed, and how it can be implemented in different cloud providers.
TL;DR
In order to have our cluster perform correctly on all the major cloud providers, we have to adapt how we scale the cluster nodes.
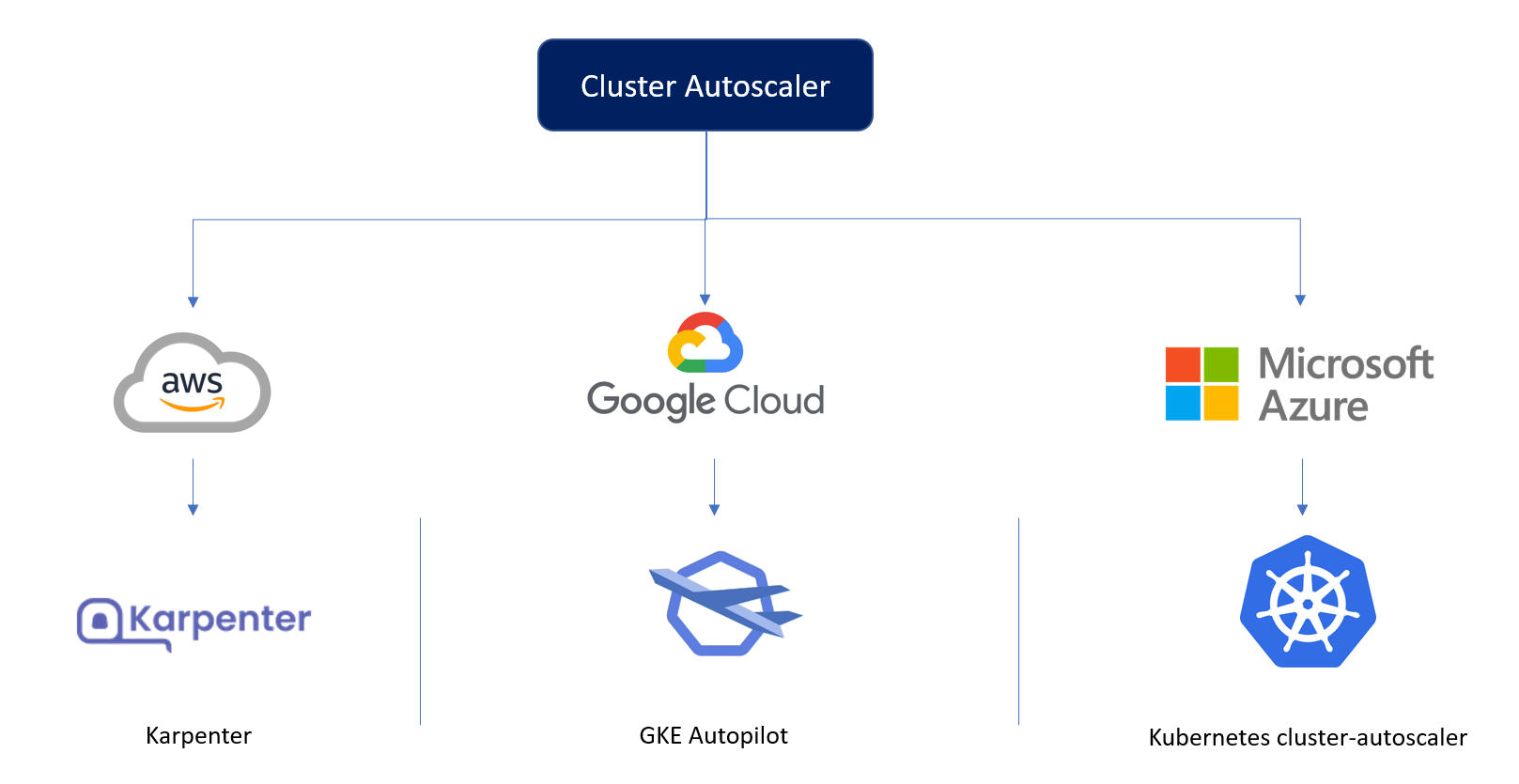
Autoscaler for AWS: Karpenter
Karpenter observes the aggregate resource requests of unscheduled pods and makes decisions to launch and terminate nodes to minimize scheduling latencies and infrastructure costs.
- Karpenter manages each instance directly and does not rely on additional orchestration mechanisms like node groups.
- Karpenter focuses on the workload and launches instances suitable for the current situation based on incoming pods' resource requests and scheduling constraints. This intent-based approach to instance selection allows for more efficient and cost-effective scaling.
But unfortunately, Karpenter works only on AWS.
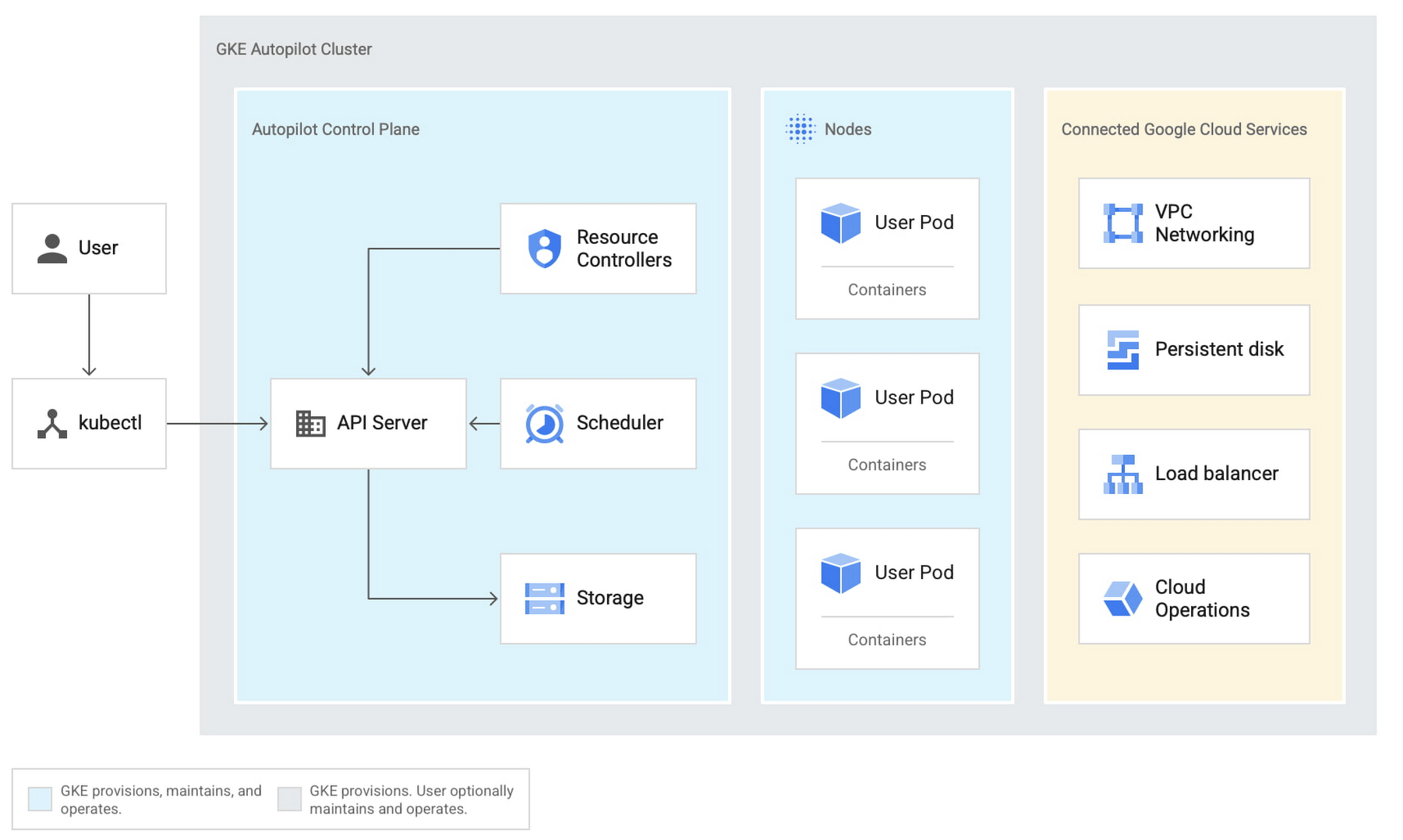
Autoscaler for GCP: GKE Autopilot
Autopilot is a managed service that uses machine learning algorithms to determine the optimal number of nodes for the cluster based on the current workload. It also provides features such as automatic upgrades and patches, making it easy to keep the cluster up-to-date and secure.
In addition to autoscaling, Cluster Autopilot also provides other benefits, such as improved resource utilization and cost savings by avoiding over-provisioning of resources. It also provides a more hands-off approach to cluster management, as all autoscaling operations are handled by the service.
Autoscaler for Microsoft Azure: Kubernetes Cluster Autoscaler
There is no managed offering on Azure cloudlike GKE Autopilot or a custom approach to autoscaling like Karpenter; therefore, we rely on cluster-autoscaler.
Kubernetes Cluster Autoscaler is an open-source tool that enables the automatic scaling of Kubernetes clusters. It runs as a pod within the cluster and monitors the resource utilization of the cluster, adjusting the number of nodes necessary to meet the needs of the applications running within it. This helps in optimizing resource utilization and reducing costs by avoiding over-provisioning of resources when demand is low. Cluster Autoscaler requires manual configuration of node groups and types.
This blog covers details on Kubernetes Autoscaling.
TrueFoundry is a ML Deployment PaaS over Kubernetes to speed up developer workflows while allowing them full flexibility in testing and deploying models while ensuring full security and control for the Infra team. Through our platform, we enable Machine learning Teams to deploy and monitor models in 15 minutes with 100% reliability, scalability, and the ability to roll back in seconds - allowing them to save cost and release Models to production faster, enabling real business value realisation.