The $360K question about Large Language Models Economics

The purpose of this article is to educate the reader about how Large Language Models (LLM) pricing works. This is motivated by our conversations with multiple companies using LLMs commercially. We realized in these conversations that LLM economics is often misunderstood, leaving a huge scope for optimization.
Do you realize that doing the same task can take either $ 3500 to do with one model or $1,260,000 with another? This does come at the cost of difference is performance, but is leaves a lot of room in the middle for thinking about what the tradeoff between cost and performance is? Is the task such that I can use something that is cheaper.


We have found companies, time and again, overestimating or underestimating their spend on Large Language Models. So here, we would try to understand the cost of running some of the popular large language models and understand how their pricing works.
Summarizing Wikipedia
The sample for pricing analysis
To understand how the pricing for LLMs work, we would be comparing the cost incurred for the same task, that is, to summarize Wikipedia to half of its size.
Details Size of the Task
We would be using some approximations to simplify the calculations and make them easily understandable
Size of the Wikipedia Corpus
- ~ 6 Million articles in total
- ~ 750 Words per article
- ~ 1000 tokens per article
The expected size of the summarized output
For this task, we assume that each article is just getting compressed to half its size for simplicity. Hence the outputs that we are expecting will be as follows:
- ~6 Million articles
- ~375 words per summarized article
- ~500 Tokens per article

Understanding the costs
Comparing what using different models would cost for this task
Levers of pricing in OpenAI/3rd Party APIs
OpenAI and other 3rd party APIs usually charge based on two levers; if you want to infer using their APIs
Input Cost
This cost depends on the number of tokens (explained above) passed as context/prompt/instruction to the API.
Output Cost
It is cost based on the number of tokens the API returns as a response.
For a task like summarization, since you need to pass the entire document or excerpt to be summarized to the model, the number of tokens that are part of the prompt can become significant, hence the input cost.
Basis of the cost incurred with self-hosted models
With self-hosted models, the user needs to manage/provision the machine that is needed to run the model. Though it may include the cost of managing these resources, the pricing is relatively easy to understand since it is just based on the running cost of the machine (usually what is charged by the cloud providers, unless you have your own on-prem cluster)
Cost of Machine
Cost of provisioning the required machine to run/host the model. Since most of these larger models are larger than what can be run on a laptop or a single local device, using a cloud provider for these machines is the most common.
Cloud providers give out these instances, though users might face GPU availability issues since these models require GPU.
Microsoft Azure Instance costs
Spot instances
Cloud providers give their spare capacity for a cost that is 40-90% cheaper than the on-demand instances
Comparing cost of the different models
GPT 4 - 8K context length
Unit Costs
| Input Cost (/Mn Tokens) | Output Cost (/Mn Tokens) |
|---|---|
| $30 | $60 |
Cost Formula
Cost = No. Of Tokens ( Per 1000 Articles) X No. of Articles (In 1000s) X Unit Cost (Per 1 Mn Tokens)
Cost of Input
1K (tokens/article) X 6,000K (articles) X $30 (/Mn tokens) = $180,000
Cost of Output
0.5 K (tokens/article) X 6,000K (articles) X $60 (/Mn tokens) = $180,000
Total Cost
Input Cost + Output Cost
= $360,000
GPT 4 - 32K context length
Unit Costs
| Input Cost (/Mn Tokens) | Output Cost (/Mn Tokens) |
|---|---|
| $60 | $120 |
Cost Formula
Cost = No. Of Tokens ( Per 1000 Articles) X No. of Articles (In 1000s) X Unit Cost (Per 1 Mn Tokens)
Cost of Input
1K (tokens/article) X 6,000K (articles) X $60 (/Mn tokens) = $360,000
Cost of Output
0.5 K (tokens/article) X 6,000K (articles) X $120 (/Mn tokens) = $360,000
Total Cost
Input Cost + Output Cost
= $720,000
Anthropic Claude V1
Unit Costs
| Input Cost (/Mn Tokens) | Output Cost (/Mn Tokens) |
|---|---|
| $11 | $32 |
Cost Formula
Cost = No. of Tokens ( Per 1000 Articles) X No. of Articles (In 1000s) X Unit Cost (Per 1 Mn Tokens)
Cost of Input
1K (tokens/article) X 6,000K (articles) X $11 (/Mn tokens) = $66,000
Cost of Output
0.5 K (tokens/article) X 6,000K (articles) X $60 (/Mn tokens) = $96,000
Total Cost
Input Cost + Output Cost
= $162,000
InstructGPT - DaVinci
Unit Costs
| Input Cost (/Mn Tokens) | Output Cost (/Mn Tokens) |
|---|---|
| $20 | $20 |
Cost Formula
Cost = No. Of Tokens ( Per 1000 Articles) X No. of Articles (In 1000s) X Unit Cost (Per 1 Mn Tokens)
Cost of Input
1K (tokens/article) X 6,000K (articles) X $20 (/Mn tokens) = $120,000
Cost of Output
0.5 K (tokens/article) X 6,000K (articles) X $20 (/Mn tokens) = $60,000
Total Cost
Input Cost + Output Cost
= $180,000
Curie
Unit Costs
| Input Cost (/Mn Tokens) | Output Cost (/Mn Tokens) |
|---|---|
| $2 | $2 |
Cost Formula
Cost = No. Of Tokens ( Per 1000 Articles) X No. of Articles (In 1000s) X Unit Cost (Per 1 Mn Tokens)
Cost of Input
1K (tokens/article) X 6,000K (articles) X $2 (/Mn tokens) = $12,000
Cost of Output
0.5 K (tokens/article) X 6,000K (articles) X $60 (/Mn tokens) = $6,000
Total Cost
Input Cost + Output Cost
= $18,000
Self-Hosted 7B Model
Unit Costs
| Cost of running Machine (/Hr for Spot A100-80Gb) |
|---|
| $10 |
Cost Formula
Cost = No. of Tokens ( Per 1000 Articles) X No. of Articles (In 1000s) X Unit Cost (Per 1 Mn Tokens)
Cost of Input
1K (tokens/article) X 6,000K (articles) X $30 (/Mn tokens) = $180,000
Cost of Output
0.5 K (tokens/article) X 6,000K (articles) X $60 (/Mn tokens) = $180,000
Total Cost
Input Cost + Output Cost
= $360,000
Fine Tuning Models
Most use cases that enterprises have to need them to fine-tune models specific to their own data and on particular tasks. Multiple companies have reported that fine-tuned open source models are at par or sometimes even better than 3rd party APIs like OpenAI on the specific task.
Fine Tuned DaVinci

Total Cost
Input Cost + Output Cost
= $1,260,000
Fine Tuned Curie

Total Cost
Input Cost + Output Cost
= $126,000
Self Hosted, Fine Tuned, 7B Model

Total Cost
Input Cost + Output Cost
= $126,000
Putting it all together
| Pretrained / Fine Tuned | Model Name | Params* | Fine tuning Cost ($) | Input Cost ($) | Output Cost ($) | Total Cost ($) |
|---|---|---|---|---|---|---|
| Pretrained | GPT-4 32K | 1 Tn + | NA | 360k | 360k | 720k |
| GPT-4 8K | 1 Tn + | NA | 180k | 180k | 360k | |
| DaVinci | 175 Bn | NA | 120k | 60k | 180k | |
| Claude v1 | 52 Bn | NA | 66k | 96k | 162k | |
| Curie | 13 Bn | NA | 12k | 6k | 18k | |
| Self-hosted 7B | 7 Bn | NA | 350 | 1750 | 2.1k | |
| Fine Tuned | DaVinci | 175 Bn | 180k | 720k | 360k | 1.26M |
| Curie | 13 Bn | 18k | 72k | 36k | 126k | |
| Self-hosted 7B | 7 Bn | 1400 | 350 | 1750 | 3.5k |
Things to notice from the pricing:
- DaVinci and Curie Models are ~7X more expensive if you are fine-tuning it on your use case
- Cost increases with an increase in context window by ~2X
- Cost of using the model Increases with an increase in the number of params of the model
Effect of fine-tuning on performance
We use the following benchmark to analyze the effect of fine-tuning of models on the performance of the models. It is interesting to notice that:
- Lower parameter models can also perform better than larger models when fine-tuned for a particular use case.
- Significant cost saving is possible without harming the performance much if the right trade-off is established between cost and performance.
| Task Type | Best 6B/7B OOTB Model Few-shot | MoveLM 7B Zero-shot | GPT-3.5 Turbo Zero-shot | GPT-3.5 Turbo Few-shot | GPT-4 Zero-shot | GPT-4 Few-shot |
|---|---|---|---|---|---|---|
| Relevance - internal dataset | 0.33 | 0.93 | 0.84 | 0.84 | 0.92 | 0.95 |
| Extraction - structured output for queries | 0.38 | 0.98 | 0.22 | 0.72 | 0.38 | 0.73 |
| Reasoning - custom triggering | 0.62 | 0.93 | 0.87 | 0.88 | 0.9 | 0.88 |
| Classification - domain of user query | 0.21 | 0.79 | 0.6 | 0.73 | 0.7 | 0.76 |
| Extraction - structured output from entity typing | 0.83 | 0.87 | 0.9 | 0.89 | 0.89 | 0.89 |
What We Are Doing
TrueFoundry believes the future of LLMs is the co-existence of open-source and commercial LLMs within the same application!
We believe in a state of applications where the easier tasks are handled by lightweight open-source LLMs, whereas the more complex tasks or the ones that require distinct capabilities (e.g., web search, API calls, etc.), which are only offered by Closed source commercial LLMs can be delegated to them.
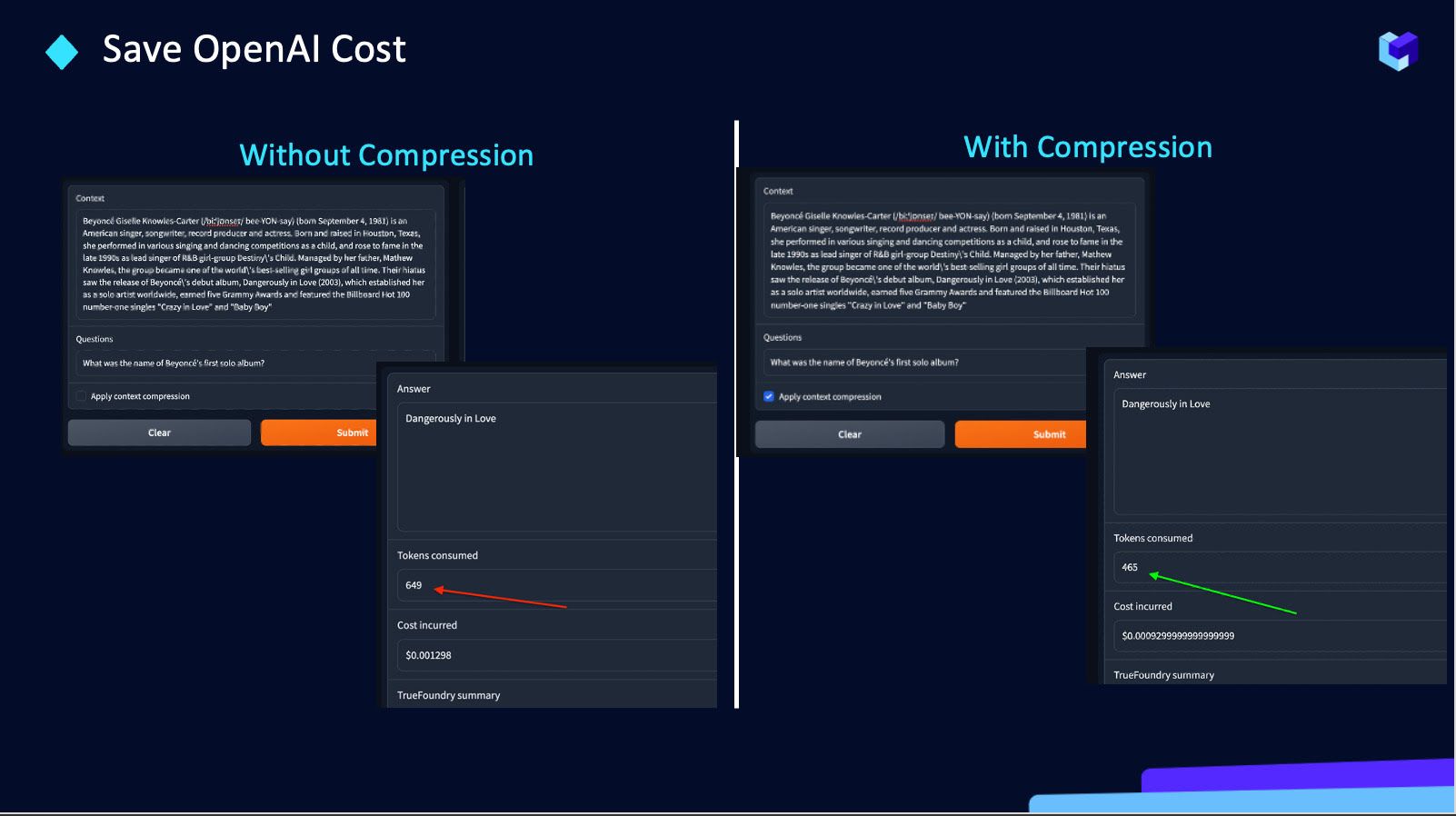
If you are using OpenAI
We help reduce the number of tokens sent to OpenAI APIs. Why we decided to work on this because:
- We noticed more than half the cost was processing context / prompt tokens.
- All words are not necessary. LLMs are great at working with incomplete sentences.
Hence TrueFoundry is building a compression API to save OpenAI cost by ~30%.
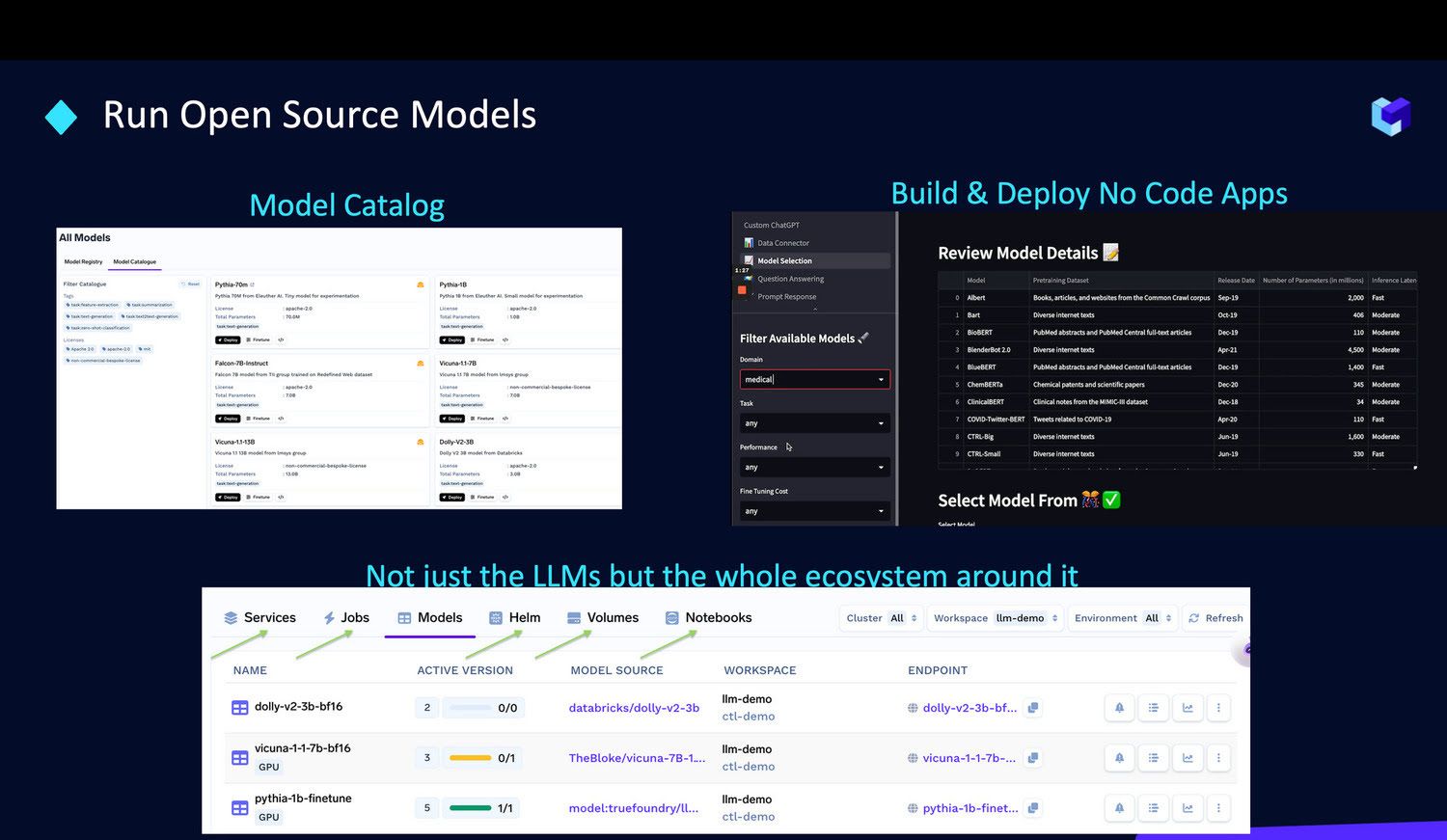
If you want to use Open Source LLMs
We simplify running these models within your own infrastructure through our following offerings:
- Model Catalogue: Of open source LLMs- optimized for inference & fine-tuning.
- Drop-in APIs: These can be directly swapped for the HuggingFace & OpenAI APIs you already run in your applications.
- Cost Optimisation: Across-cloud on K8s by leveraging your cloud credits or budget.