An impactful ML Model - how hard can it be?

Building a model to solve a business usecase sounds like a great idea to all of us. It seems intuitive that if we can increase engagment through personalization on a certain website using ML by 5%, it will push revenues up by some percent.
However, what often gets overlooked are two factors that can jeopardize this project:
- If there is enough data to make a model that can indeed increase personalization by 5%
- Investment needed to get that model built and deployed which is providing that impact on a continual basis.
Well, shouldn't it be simple to test out the 2 things ? Well let's go into the depth of what it takes to go from an idea of building a model to finally getting the model in production and evaluating business impact. Let's consider the case where in a food delivery app wants to show the expected time of delivery once a customer places an order on the app. Since we don't know the delivery time beforehand, we will need to build an ML model that can do the prediction based on certain factors like the city, restaurant, time of day, distance from customer to restaurant, etc.
Show the estimated delivery time to user for a food delivery app
The workflow getting this model out will involve the following teams:
Project Ideation
The Product Manager will come up with the project to estimate the delivery time. The expectation is that if the delivery time is decently accurate, it will provide a better experience to users. There will be lesser queries from customers related to delivery times and overall customer satisfaction score should go up. The business team will then ask the data science team to come up with this model.
Data Gathering
Data-scientists starts gathering the historical data of all orders made and their delivery times.
- In some cases, previous data might not be logged properly - log the data and collect it first (Product Team, Data Engineering Team).
- In some fortunate cases this data might be easily available
- In many cases, this will require ETL pipelines to be written to get the data in the right format. The Data Engineering team will write the pipelines to get the data in the required format.
Data Analysis
The data scientist will then analyze the data to see if everything looks correct - no null or bogus values and if all the required data is there. A lot of times - the DS will spot a few bugs in the dataset - or maybe there are a few days of bad data due to some transient bugs. We will need to weed out the bogus data since then only we can build a good model. This can lead to a few iterations with the Product and Data Engineering team.
Feature Engineering
Once the data looks good, in some cases data scientists will want to have a pipeline for calculating features and storing the features so that there is no training-serving skew and its easier to get the feature values during inference.
However this is an optional step and is skipped when the data or number of models built on the same dataset is small. In case a team decides to do feature engineering, we will need a pipeline orchestration system like Airflow, Prefect and a database / cache to store the features for retrieval (for e.g. Feast). Building a feature store is in itself a huge undertaking and requires significant effort.
Model Training
Once the data is all ready, the data scientist will now experiment with different algorithms, features and models to find out which performs the best. They would want to log all the metrics, parameters and models so that they can refer back to it later or share with other team members. This is where an experiment tracking and a model metadata store comes in.
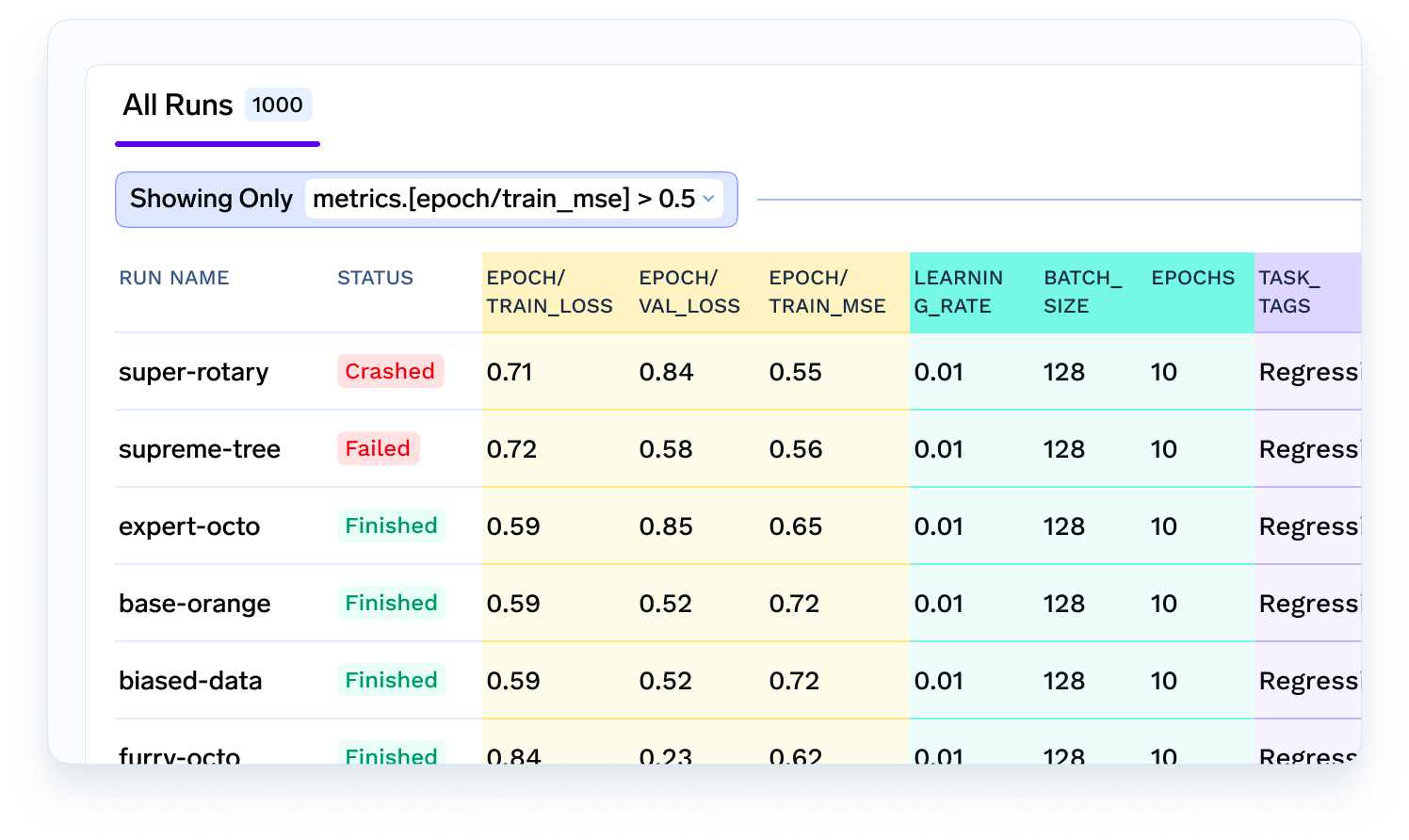
Model Serving
Once the model is built, the model needs to be hosted as a microservice or as a batch inference job. In our case of delivery time prediction, this needs to be a realtime online service - so it probably makes sense to deploy it as an autoscaling service. In this case, an ML engineer steps in who takes the model, wraps it in a Flask or FastAPI service and builds the docker image. Then the ML Engineer along with the help of Devops team will deploy it as a microservice on the infrastructure.
Product Integration
Once the model API is hosted, the product or backend team will need to call the API in their code to utilize the predicted delivery time and show it on the app. This will require collaboration between the Data scientist, Product and ML Engineering teams. During this time, the Product Manager might want to test out the predictions and it will be great if they can quickly test the model on some sample inputs. This might require a quick model demo to be built.
Model Monitoring
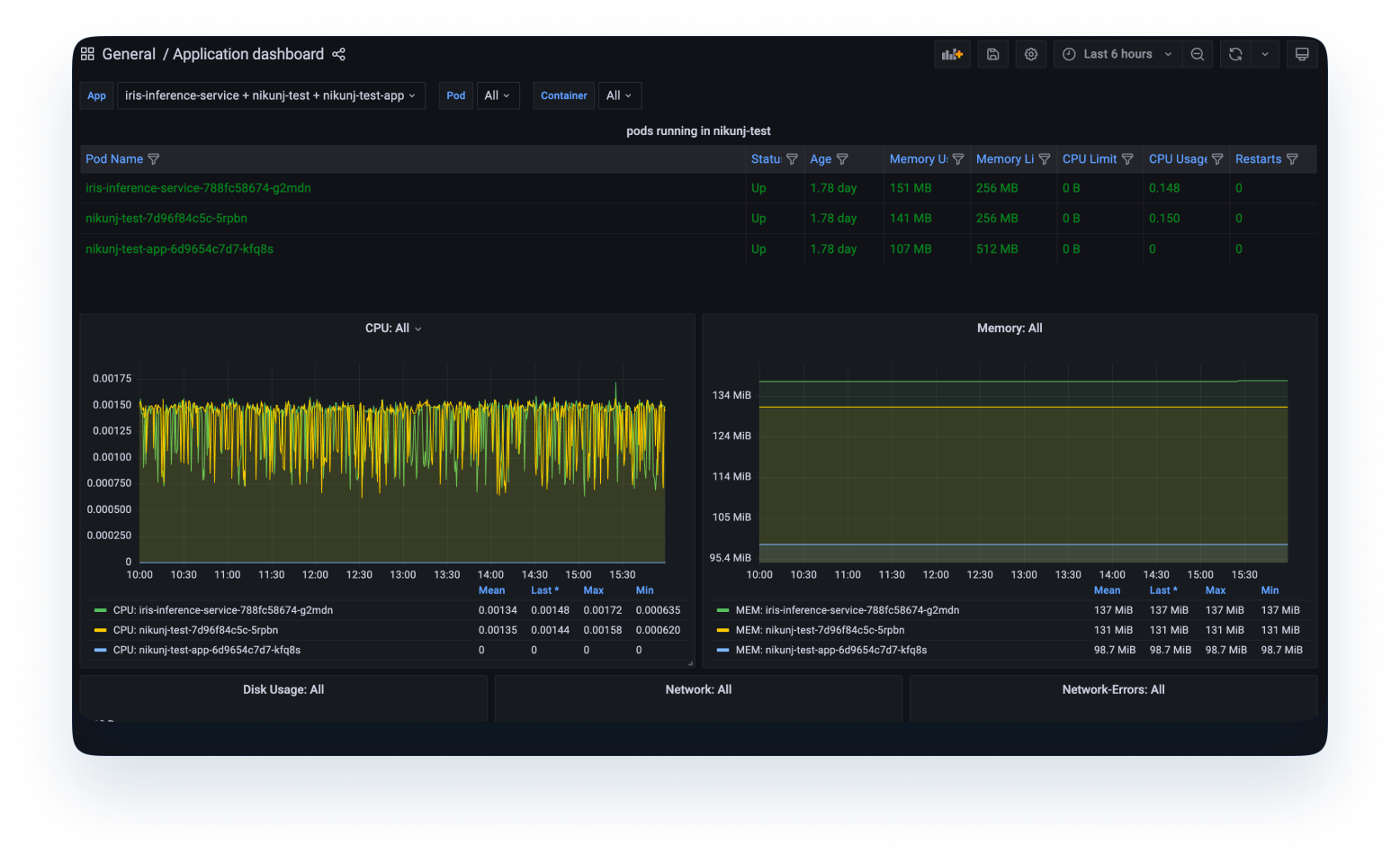
Once the model is deployed and is being used in the product, we will need metrics on the deployed model.
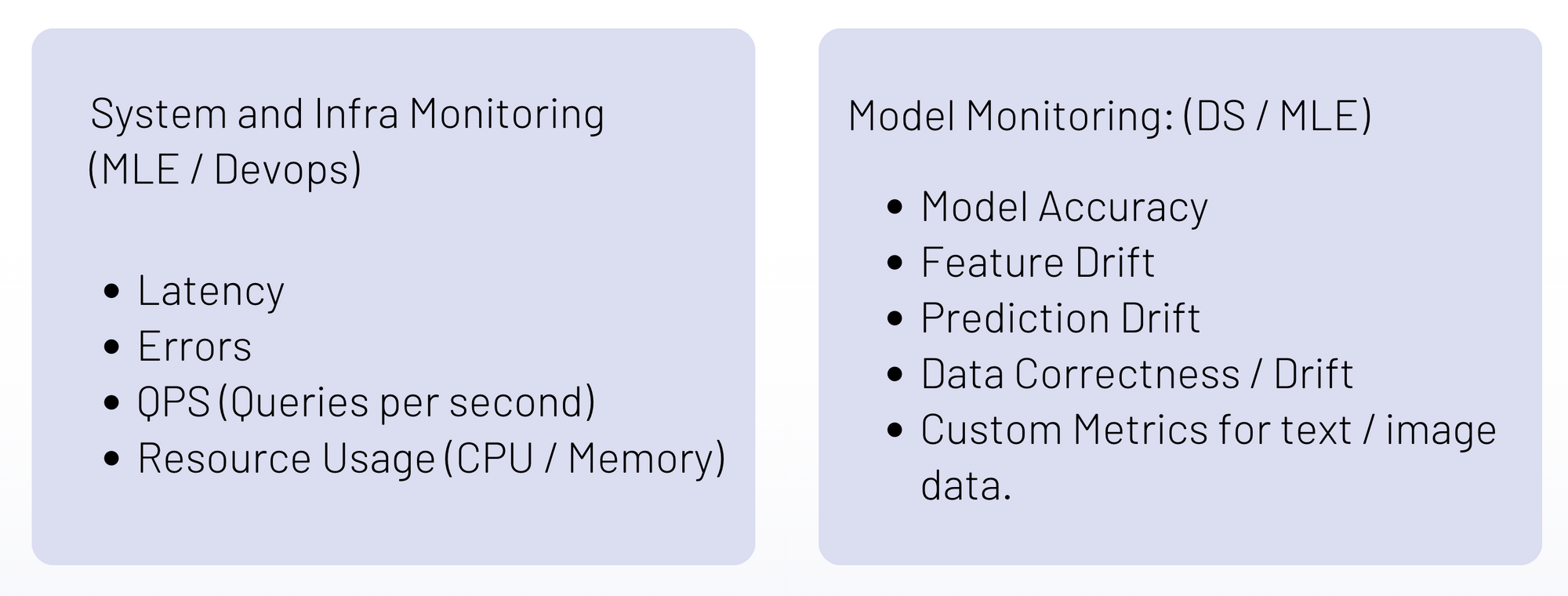
- System Monitoring: This includes metrics like cpu, memory, api latency, errors, crashes of the model and usually done using Prometheus / Grafana or paid solutions like Datadog / New Relic. This will be used by Engineering, Product and the Datascience team.
2. Model Monitoring: This includes the metrics related to the model prediction on the incoming production data. This is data that the Data Scientist will primarily be interested in and includes metrics like model accuracy, feature drift, prediction drift, etc. This helps the data scientist decide whether the model is behaving in a similar way as it was during training, the external input data distributions have not changed and whether there are no bugs anywhere else in the system.
To get complete monitoring around the model, it will require significant efforts from the Datascience, Engineering and Devops teams.
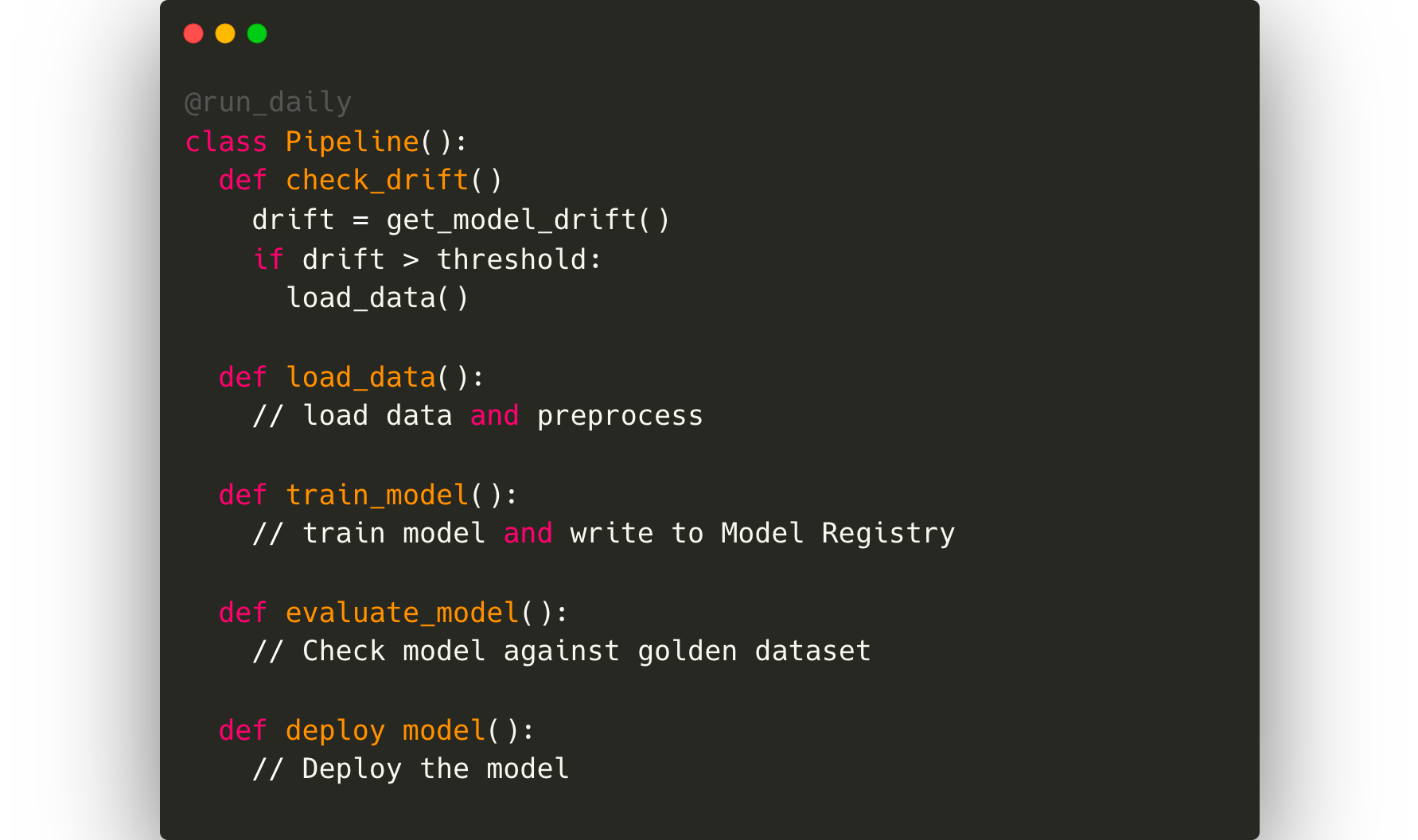
Complete Automation
Once all monitoring has been sorted, the datascientist will ideally want to automate the complete retraining loop. This will require a pipeline orchestration framework like Kubeflow or Airflow.
Evaluation of Business Impact:
We then need to also estimate the impact of this model on the actual user satisfaction metrics. A few proxy metrics in this case will be the number of customer queries related to delivery times, overall satisfaction score of customers for an order. The business metrics will need to be joined with the model metrics and the Data Engineering team will probably write an ETL pipeline to get this data and plot it out on internal dashboarding tool for business leaders to observe.
To sum up roughly, this involves 5 stakeholders:
- Product Manager / Business team
- Data Engineering Team
- Data Science Team
- ML Engineering Team
- Backend Engineering Team
- Devops Team
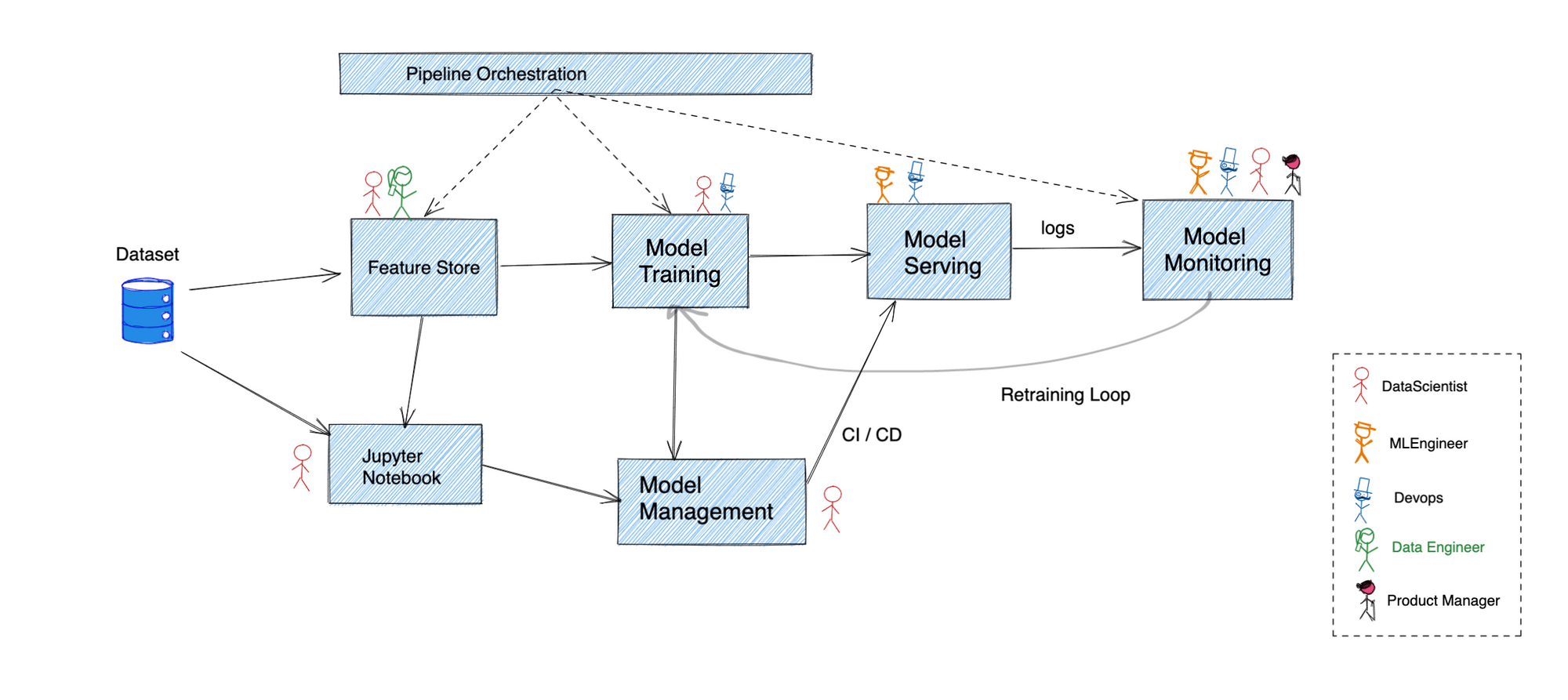
The overall procests easily takes up over 2-3 months in any company and can sometimes go as long as 6 months for the first few models. Its because of multiple stakeholders involved and multiple skillsets involved that making ML impactful takes so much time and initial upfront investment.
We haven't yet talked about some of the scalability and reliability aspects involved in the process. We hope to cover some of the aspects below in a future article.
- Provisioning of infrastructure
- CI / CD process
- Model Experimentation including A/B Testing.
- Scalablity of Infrastructure.
- Choice of deployment methodology.
The solution here is to automate the parts that can be automated and provide the autonomy to data scientist / ML engineer to perform most of the steps without learning all the tools involved. There is a lot of work happening in this domain and hopefully in a few years, making an impactful ML model becomes as easy as building a landing page today!