LLMOps: Mastering the Art of Managing Large Language Models - Challenges, Components, and Top Platforms

Table of Contents
- Introduction to LLMOps
- Essential Components of LLMOps
- Benefits and Advantages of LLMOps
- LLMOps Platforms and Tools
- Conclusion
Introduction to LLMOps
LLMOps and its role in managing large language models
LLMOps, also known as Large Language Model Operations, encompass the specialized practices and processes essential for efficiently managing and operationalizing large language models (LLMs). LLMs are advanced natural language processing models that have the capability to generate human-like text and perform a wide range of language-related tasks. These models are a significant advancement in AI and have found applications in various domains such as chatbots, translation services, content generation, and more.
The role of LLMOps is to ensure the smooth development, deployment, and maintenance of LLMs throughout their lifecycle. It involves various stages, from data acquisition and preprocessing to fine-tuning the model, deploying it into production, and continuously monitoring and updating it to ensure optimal performance.
Challenges faced in developing and deploying LLMs
Developing and deploying Large Language Models come with a unique set of challenges due to their complexity and resource-intensive nature:
- Enormous Computational Resources: Training LLMs requires vast amounts of computational power and memory. Training even a single large model can be prohibitively expensive and time-consuming.
- Data Requirements: LLMs require massive datasets for training to achieve high-quality results. Acquiring, cleaning, and annotating such large-scale data can be challenging and costly.
- Ethical Concerns: As LLMs become more powerful, there are concerns about the potential for misuse, such as generating fake content or biased outputs.
- Model Interpretability: Understanding how LLMs arrive at their decisions can be challenging, making it difficult to explain their behaviour and ensure transparency.
- Transfer Learning and Fine-Tuning: Fine-tuning pre-trained LLMs on specific tasks requires careful optimization to prevent catastrophic forgetting and ensure good generalization.
- Deployment Scaling: Deploying LLMs in a production environment requires efficient scaling to handle high volumes of incoming requests without compromising performance.
How are LLMOps from MLOps different?
While LLMOps share similarities with traditional MLOps (Machine Learning Operations), there are some distinct aspects that set them apart:
- Language-Specific Challenges: LLMs deal with language-related tasks, which often involve textual inputs and outputs, making data preprocessing and augmentation language-specific.
- Prompt Engineering: Crafting effective prompts are crucial for guiding LLM behaviour, and LLMOps involve iterative experimentation to optimize prompts for desired outputs.
- Human Feedback Loop: Incorporating human feedback is vital to continuously improve LLM performance, requiring a feedback loop for model refinement.
- Computational Demands: Due to the size and complexity of LLMs, deploying and managing them requires specialized infrastructure and computational resources.
- Transfer Learning Dominance: Pre-training and fine-tuning are central to LLM development, as these models heavily rely on transfer learning from large pre-trained models.
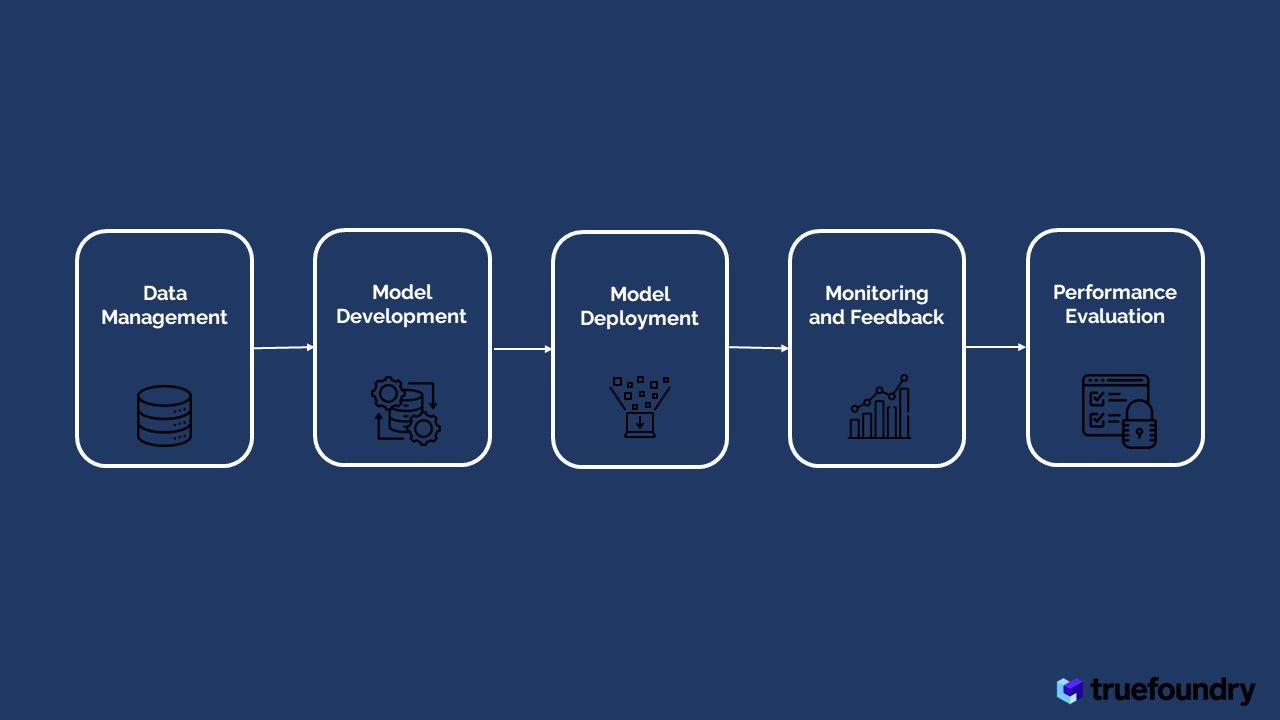
Essential Components of LLMOps
Data Management: Sourcing, preprocessing, and labelling data for LLM training
Data is the cornerstone of every successful Large Language Model (LLM) - a powerful tool that has revolutionized natural language processing. However, the journey from raw data to a high-performing LLM involves a series of crucial steps in data management. In this section, we will delve into the intricacies of data sourcing, preprocessing, labelling, and model development, illuminating the challenges and best practices that LLMOps teams face in this crucial stage of AI language excellence.
Data Collection: Unearthing the Gems
Gathering diverse and representative data is a monumental challenge that can significantly impact the efficacy of an LLM. LLMOps teams traverse the vast expanse of the web, curating multitudes of texts, conversations, and documents to create a robust and comprehensive dataset. Strategies such as web scraping, leveraging open-source repositories, and collaborating with domain experts enable teams to build datasets that reflect the real-world complexity of language.
Data Preprocessing: Refining the Raw Material
Once collected, data undergoes rigorous preprocessing to be ready for LLM training. Cleaning the data involves removing noise, and irrelevant information, and handling misspellings and grammatical errors. Tokenization breaks down the text into meaningful units, such as words or subwords, allowing the model to process and understand the language better. Normalization ensures uniformity by converting text to a standard format, reducing potential discrepancies during training.
Data Labeling: Unveiling Insights through Supervision
Supervised learning demands labelled data, and LLMOps teams invest substantial effort in creating annotated datasets for specific LLM tasks. Manual annotation by human experts or crowd-sourcing platforms aids in providing labels for sentiment analysis, named entity recognition, and more. Techniques like active learning and data augmentation further optimize labelling efforts, effectively utilizing resources to achieve better model performance.
Vector Databases
Large language models (LLMs) are becoming increasingly important in a variety of applications, such as natural language processing, machine translation, and question-answering. However, LLMs can be complex and difficult to manage. Vector databases can help to simplify the management of LLMs by providing a way to store and search their large vector representations.
A vector database is a type of database that stores data in the form of vectors. Vectors are a type of mathematical object that can be used to represent complex data, such as text, images, and audio. Vector databases are well-suited for storing and searching LLMs because they can efficiently store and retrieve the large vector representations that LLMs use.
There are a number of vector databases available, including Pinceone, Milvus, Vespa AI, Qdrant, Redis, SingleStore, Weviate etc. These vector databases provide a variety of features that can be used to manage LLMs. Here are some specific examples of how vector databases can be used in LLMOps:
- Storing and searching vector representations: Vector databases can be used to store and search the large vector representations that LLMs use. This makes it easy to find and use LLMs for a variety of tasks. For example, a company that develops chatbots could use a vector database to store the vector representations of different chatbot models. This would make it easy to find the best chatbot model for a particular task, such as customer service or sales.
- Version control: Vector databases can track the changes that are made to LLMs. This makes it easy to reproduce experiments and keep track of the evolution of LLMs over time. For example, a research team that is developing a new LLM could use a vector database to track the changes that are made to the LLM's parameters. This would make it easy to reproduce experiments that were run with the LLM and to keep track of how the LLM's performance has improved over time.
- Experiment tracking: Vector databases can track the results of experiments that are run with LLMs. This makes it easy to identify the best LLM configuration for a particular task. For example, a company that is developing a new machine translation model could use a vector database to track the results of experiments that are run with different model configurations. This would make it easy to identify the model configuration that produces the best translations.
- Production deployment: Vector databases can be used to deploy LLMs to production. This makes it easy to make LLMs available to users. For example, a company that is developing a new question-answering system could use a vector database to deploy the system to production. This would make it possible for users to ask questions of the system and to receive answers.
Model Development: Architectural selection, experiment tracking, fine-tuning, and hyperparameter tuning
Model development lies at the heart of Large Language Model Operations (LLMOps), where the quest for optimal performance and language brilliance begins. In this pivotal stage, LLMOps teams embark on a journey of architectural selection, fine-tuning, and hyperparameter tuning to shape language models into proficient and versatile entities. In this comprehensive exploration, we delve into the intricacies of each step, shedding light on the challenges and cutting-edge techniques that fuel AI language excellence.
Architectural Selection: Crafting the Model's Foundation
Choosing the right LLM architecture is a decisive factor that profoundly influences its capabilities. LLMOps teams meticulously evaluate various architectural options, considering factors such as model size, complexity, and the specific requirements of the intended tasks. Transformer-based architectures, such as the GPT (Generative Pre-trained Transformer) family, have revolutionized the field of natural language processing. However, novel architectures that incorporate innovations like attention mechanisms, memory augmentation, and adaptive computations are continuously explored to address specific challenges, enhance performance, and cater to diverse applications.
Streamlining Progress: The Power of Experiment Tracking in Large Language Model Operations
Experiment tracking is a crucial aspect of Large Language Model Operations (LLMOps), empowering teams to systematically manage and analyze the myriad of experiments conducted during LLM development. By implementing robust tracking frameworks, LLMOps teams efficiently log model configurations, hyperparameters, and outcomes, enabling data-driven decisions. It fosters reproducibility, transparency, and collaboration, aiding in the refinement process and aligning model responses with user expectations. Experiment tracking plays a pivotal role in the human-in-the-loop approach, incorporating valuable feedback and driving us closer to the realization of AI-language intelligence at its finest.
Fine-Tuning Strategies: Refining for Task Excellence
Pre-trained LLMs serve as the starting point for task-specific fine-tuning. This process involves adapting the model's knowledge and understanding to excel in targeted tasks. LLMOps teams skillfully navigate the fine-tuning landscape, striking the right balance between retaining the model's pre-trained knowledge and incorporating task-specific information. Selecting appropriate hyperparameters, including learning rates, batch sizes, and optimization algorithms, plays a pivotal role in achieving the desired performance. Moreover, the amount of additional training data required for fine-tuning is thoughtfully determined to avoid overfitting or underutilizing the model's potential.
Hyperparameter Tuning: Unleashing the Model's Potential
Hyperparameters serve as the dials that control the model's behaviour during training. Finding the optimal configuration of these hyperparameters is a critical step in maximizing the model's performance. LLMOps teams employ a variety of techniques to embark on the hyperparameter tuning journey. From grid search to Bayesian optimization and evolutionary algorithms, each method explores the vast hyperparameter space to identify the sweet spot where the model achieves its peak performance. Additionally, approaches like learning rate schedules and weight decay are leveraged to enhance generalization and mitigate overfitting.
Transfer Learning and Multitask Learning: Empowering Adaptability
LLMOps teams leverage transfer learning and multitask learning paradigms to enhance model adaptability and efficiency. Transfer learning involves pre-training a language model on a massive corpus, followed by task-specific fine-tuning. This technique empowers the model to benefit from the knowledge distilled from a diverse range of language data. Multitask learning allows models to simultaneously learn from multiple tasks, enabling them to leverage the relationships and common patterns across tasks, leading to better generalization and performance.
Model Deployment and Operation: Strategies for Deployment and Collaboration
The success of Large Language Models (LLMs) hinges not only on their impressive capabilities but also on their seamless deployment and efficient operations. In this crucial phase of Large Language Model Operations (LLMOps), meticulous planning and execution are paramount. This section delves into the intricacies of model deployment strategies, the significance of continuous monitoring and maintenance, and the invaluable role of human feedback and prompt engineering in shaping LLMs to achieve AI language excellence.
Deployment Strategies: Setting the Stage for LLM Performance
The deployment of LLMs in production environments demands strategic considerations to ensure optimal performance and user satisfaction. LLMOps teams meticulously evaluate deployment strategies, taking into account infrastructure requirements, scalability, and performance considerations. Cloud-based deployment offers flexibility and on-demand resources, while on-premises solutions cater to data privacy and security concerns. Edge deployment empowers LLMs to operate closer to end-users, reducing latency and enhancing real-time interaction. Adopting the most suitable deployment strategy enhances the LLM's availability and responsiveness, meeting the diverse needs of applications in the real world.
Interdisciplinary Collaboration: Fostering AI-Language Brilliance
The deployment and operations of LLMs require a holistic and collaborative approach. LLMOps teams collaborate with domain experts, ethicists, and user interface designers to address challenges comprehensively. Involving experts from various fields ensures that LLMs are tailored to serve specific industries and domains effectively. Ethical considerations play a crucial role in mitigating bias and ensuring responsible AI deployment, creating LLMs that are fair, inclusive, and equitable in their interactions with users. User interface designers enhance the overall user experience, making LLMs more intuitive and user-friendly, promoting seamless and productive interactions.
Continuous Integration and Delivery (CI/CD): Automating model development and deployment
Continuous Integration (CI) is the practice of automating the building and testing of code every time it is committed to a version control system. This helps to ensure that the code is always in a working state and that any changes are quickly identified and addressed.
Continuous Delivery (CD) is the practice of automating the deployment of code to a production environment. This helps to ensure that code can be deployed quickly and reliably and that any changes are rolled back if necessary.
When CI and CD are combined, they form a CI/CD pipeline. A CI/CD pipeline can automate the entire process of building, testing, and deploying machine learning models. This can help to improve the reliability, efficiency, and visibility of the machine learning model development and deployment process.
Here are some of the benefits of using CI/CD for LLMOps:
- Increased reliability: CI/CD can help to reduce the risk of errors in machine learning models by automating the testing process. This is because the tests are run automatically every time the code is changed, which helps to identify and fix any errors early on.
- Improved efficiency: CI/CD can help to speed up the process of deploying machine learning models by automating the deployment process. This is because the deployment process is automated, which means that there is no need for manual intervention.
- Increased visibility: CI/CD can help to improve visibility into the machine learning model development and deployment process. This is because all of the steps in the process are tracked and recorded, which makes it easier to identify any problems that may occur.
Here are some examples of CI/CD tools for LLMOps:
- GitLab: GitLab is a popular DevOps platform that includes CI/CD features.
- Jenkins: Jenkins is another popular CI/CD tool.
- CircleCI: CircleCI is a cloud-based CI/CD platform.
These are just a few of the benefits of using CI/CD for LLMOps. If you are looking to improve the reliability, efficiency, and visibility of your machine learning model development and deployment process, then CI/CD is a valuable tool to consider.
Monitoring, Prompt Engineering and Human Feedback
Monitoring and Maintenance: Safeguarding LLM Efficiency
Continuous monitoring is the heartbeat of successful LLM operations. It allows LLMOps teams to identify and address issues promptly, ensuring peak performance and reliability. Monitoring encompasses performance metrics, such as response time, throughput, and resource utilization, enabling timely intervention in case of bottlenecks or performance degradation. Additionally, detecting bias or harmful outputs is critical for responsible AI deployment. By employing fairness-aware monitoring techniques, LLMOps teams ensure that LLMs operate ethically, reducing unintended biases and enhancing user trust. Regular model updates and maintenance, facilitated by automated pipelines, guarantee that the LLM remains up-to-date with the latest advancements and data trends, guaranteeing sustained efficiency and adaptability
Human Feedback and Prompt Engineering: Nurturing AI-Language Intelligence
Human feedback serves as a crucial driving force in refining LLM performance. LLMOps teams adopt a human-in-the-loop approach, enabling experts and end-users to provide valuable feedback on the LLM's outputs. This iterative process facilitates model improvement and fine-tuning, aligning the LLM's responses with human expectations and real-world needs. Reinforcement learning from human feedback (RLHF) is a machine learning technique that trains models to generate text that is aligned with human preferences. RLHF works by giving the model a reward signal for generating text that is considered "good" by a human evaluator. The model then learns to generate text that will maximize the reward signal. RLHF can be used to improve the performance of LLMs in a variety of tasks, such as text summarization, question answering, and dialogue generation. By combining human feedback with machine learning, RLHF can create models that are more accurate, informative, and engaging.
Furthermore, prompt engineering plays a pivotal role in guiding LLMs to produce desired outputs. Crafting appropriate prompts helps direct the model's responses, allowing LLMOps teams to experiment and optimize prompts for different use cases, domains, and user preferences. As a result, LLMs become more controllable, adaptable, and efficient in delivering meaningful responses
Ensuring Excellence: Thorough Testing in Large Language Model Operations
Testing is an integral aspect of Large Language Model Operations (LLMOps) that ensures the robustness and reliability of LLMs in real-world scenarios. Thorough testing procedures help LLMOps teams validate the performance and accuracy of the language model across a diverse range of tasks and input scenarios. Various testing methodologies, including unit testing, integration testing, and end-to-end testing, are employed to assess different aspects of the LLM's functionality. Additionally, stress testing and adversarial testing aid in identifying potential weaknesses or vulnerabilities in the model's responses, ensuring that it can handle challenging inputs and adversarial examples with poise. By conducting rigorous testing, LLMOps teams instil confidence in the model's capabilities, fostering responsible and impactful deployment of LLMs in practical applications.
Performance Metrics and Evaluation: Unique metrics and scoring methods for LLMs.
Evaluating the performance of Large Language Models (LLMs) is crucial in assessing their capabilities and potential for various natural language processing tasks. Numerous evaluation methods exist, each shedding light on different aspects of a model's effectiveness. Below are five commonly used evaluation dimensions that offer valuable insights into the performance of LLMs:
Perplexity
Perplexity is a fundamental measure frequently used to assess language model performance. It quantifies how effectively the model predicts a given sample of text. A lower perplexity score indicates that the model can better predict the next word in a sequence, suggesting a more coherent and fluent output. This metric helps researchers and developers fine-tune their models for improved language generation and comprehension.
Human Evaluation
While automated metrics are valuable, human evaluation plays a pivotal role in assessing the true quality of language models. For this approach, expert human evaluators are enlisted to review and rate the generated responses based on multiple criteria, such as relevance, fluency, coherence, and overall quality. The human judgment provides subjective feedback and captures nuances that automated metrics might overlook. It is a crucial step in understanding how well the model performs in real-world scenarios and enables researchers to address any specific concerns or limitations.
BLEU (Bilingual Evaluation Understudy)
Primarily used in machine translation tasks, BLEU compares the generated output with one or more reference translations to measure the similarity between them. A higher BLEU score indicates that the model's generated translation aligns well with the provided reference translations. It helps assess the model's translation accuracy and effectiveness.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
ROUGE is a set of metrics extensively employed for evaluating the quality of text summarization. It measures the overlap between the generated summary and one or more reference summaries, considering precision, recall, and F1-score. ROUGE scores provide valuable insights into how well the language model can generate concise and informative summaries, making it invaluable for tasks such as document summarization and content generation.
Diversity Measures
Ensuring that a language model produces diverse and unique outputs is essential, especially in applications like chatbots or text generation systems. Diversity measures involve analyzing metrics such as n-gram diversity or measuring the semantic similarity between generated responses. Higher diversity scores indicate that the model can produce a broader range of responses and avoid repetitive or monotonous outputs.
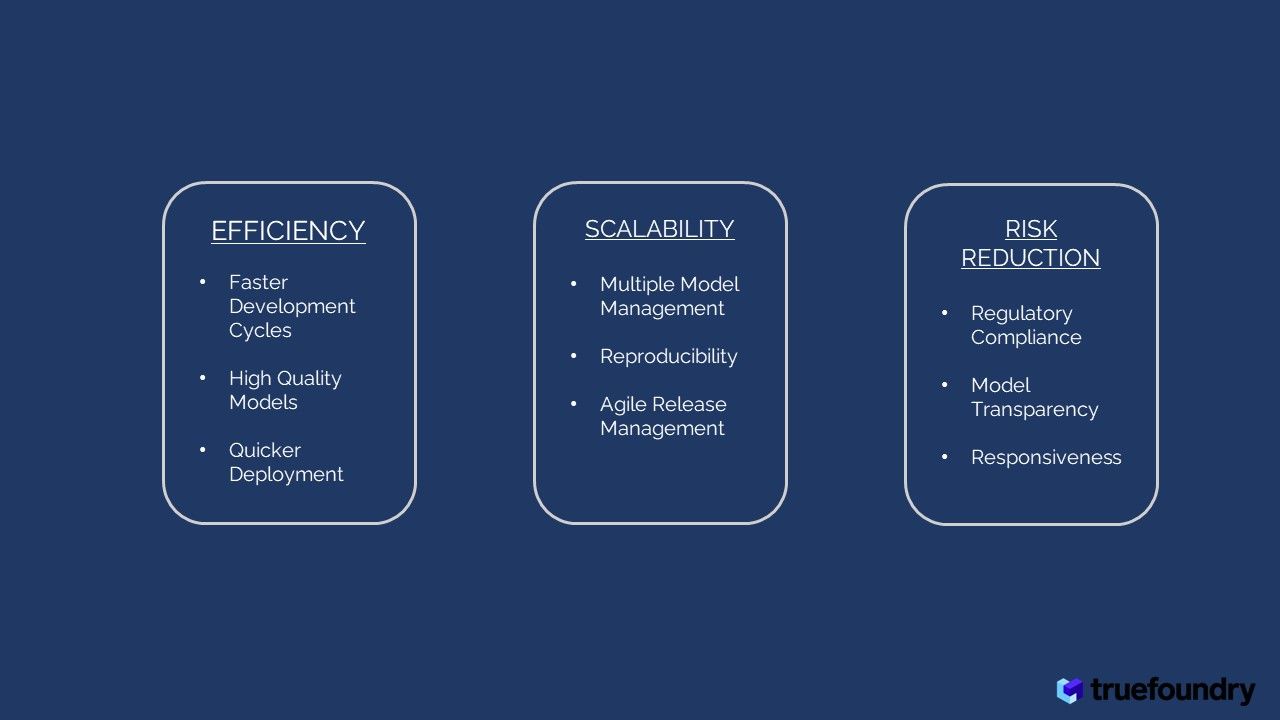
Benefits and Advantages of LLMOps
Efficiency: Accelerated model and pipeline development, improved model quality, and faster production deployment.
LLMOps streamline the LLM development process, leading to several benefits:
- Faster Development Cycles: Efficient data management and fine-tuning techniques accelerate the overall model development cycle.
- High-Quality Models: Proper monitoring, evaluation, and optimization based on human feedback results in improved model quality.
- Quicker Deployment: Optimized deployment strategies and well-managed operations enable faster deployment of LLMs in real-world applications.
Scalability: Managing and overseeing a large number of models, reproducibility of LLM pipelines, and increased release velocity.
LLMOps support the scalability and reproducibility of LLM pipelines:
- Multiple Model Management: LLMOps provide infrastructure and tools to handle multiple LLMs effectively, each serving different tasks or languages.
- Reproducibility: Proper version control and documentation ensure that LLM pipelines are reproducible, making it easier to track changes and roll back if needed.
- Agile Release Management: Efficient LLMOps practices enable quicker and smoother model updates and deployments, supporting rapid release velocity.
Risk Reduction: Ensuring compliance with regulations, transparency in model development, and faster response to requests.
LLMOps addresses potential risks associated with LLM deployment:
- Regulatory Compliance: Transparent model development and ethical considerations help ensure compliance with regulations and guidelines.
- Model Transparency: LLMOps aims to make LLM behaviour more interpretable, reducing the risk of biased or undesirable outputs.
- Responsiveness: Efficient LLMOps practices enable faster responses to requests, reducing potential delays and improving user experience.
In conclusion, LLMOps play a vital role in managing the complex and resource-intensive process of developing, deploying, and maintaining Large Language Models. By addressing unique challenges and leveraging specialized techniques, LLMOps ensure the efficient and ethical use of these powerful AI models in various real-world applications.
LLMOps Platforms and Tools
End-to-End Platforms
HuggingFace
HuggingFace is an open-source platform for building and using large language models. It provides a library of pre-trained models, a command-line interface, and a web app for experimenting with models. HuggingFace's speciality is its focus on making large language models accessible to everyone.
HuggingFace's library of pre-trained models includes a wide variety of models, from BERT to GPT-3. These models can be used for a variety of tasks, such as natural language understanding, natural language generation, and question answering. HuggingFace's command-line interface makes it easy to load and use these models, and its web app provides a visual interface for experimenting with models.
ClearML
ClearML is a platform for managing machine learning experiments. It provides a way to track experiments, store data, and visualize results. ClearML's speciality is its ability to track experiments across multiple machine learning platforms. ClearML's experiment tracking features make it easy to keep track of the progress of your machine learning projects. You can track the parameters that you used, the metrics that you measured, and the results that you achieved. ClearML also allows you to store data from your experiments, so you can easily reproduce your results.
AWS Sagemaker
AWS SageMaker is a fully managed platform that provides a comprehensive set of capabilities for building, training, and deploying machine learning models. It includes a variety of tools and services for managing the entire machine-learning lifecycle, from data preparation to model deployment. SageMaker is a popular choice for LLMOps because it provides a number of features that are specifically designed for large language models, such as:
- Distributed training: SageMaker can be used to train large language models on distributed clusters of machines. This allows for faster training times and better performance.
- Model monitoring: SageMaker provides tools for monitoring the performance of large language models. This helps to ensure that the models are performing as expected and that they are not being adversely affected by changes in the data or the environment.
- Model deployment: SageMaker can be used to deploy large language models to production. This allows the models to be used to power applications and services.
Bedrock
Bedrock is a new platform from AWS that is specifically designed for generative AI. It provides a number of features that are designed to make it easier to build, train, and deploy generative AI models, including:
- A library of pre-trained generative AI models: Bedrock includes a library of pre-trained generative AI models that can be used as a starting point for building new models.
- A framework for training generative AI models: Bedrock provides a framework for training generative AI models that makes it easier to experiment with different training parameters and configurations.
- A platform for deploying generative AI models: Bedrock provides a platform for deploying generative AI models that makes it easy to scale the models to production.
Azure OpenAI services
Azure OpenAI services are a set of services that allow you to use OpenAI's large language models in Azure. These services include a managed endpoint for the GPT-3 family of models, a text-to-code service, and a question-answering service. Azure OpenAI services' speciality is its integration with Azure. Azure OpenAI services make it easy to use OpenAI's large language models in your Azure applications. You can use the managed endpoint to get access to a GPT-3 model, or you can use the text-to-code service to generate code from natural language descriptions. Azure OpenAI services also provide a question-answering service, so you can ask questions about OpenAI's models and get answers.
GCP Palm API
GCP Palm API is a natural language processing API that can be used to generate text, translate languages, and answer questions. It is based on Google's LLMs, such as BERT and GPT-3. GCP Palm API's speciality is its ability to generate text, translate languages, and answer questions. GCP Palm API provides a variety of features for generating text, translating languages, and answering questions. You can use it to generate realistic text, translate languages accurately, and answer questions in a comprehensive and informative way. GCP Palm API is a powerful tool for developers who need to use natural language processing in their applications.
Data Management: Sourcing, preprocessing, and labelling data for LLM training
LlamaIndex
LlamaIndex is a platform for indexing and searching large language models. LlamaIndex is particularly well-suited for LLMOps, as it provides a variety of features for indexing and searching LLMs, including fast querying, relevance ranking, and faceting. LlamaIndex's fast querying feature allows you to quickly search your LLMs for the information you need. The relevance ranking feature allows you to rank the results of your searches based on their relevance to your query. The faceting feature allows you to filter the results of your searches by different criteria.
LangChain
LangChain is an LLMOps platform that helps teams build, deploy, and manage large language models (LLMs) at scale. It provides a variety of features for managing LLMs, including version control, experiment tracking, and production deployment. LangChain's speciality is its ability to scale LLMs to handle large amounts of data. It also provides a variety of features for monitoring LLMs, so teams can ensure that they are performing as expected.
Toloka
Toloka is a crowdsourcing platform that allows you to label data for machine learning models. Toloka is particularly well-suited for LLMOps, as it can be used to label large amounts of data quickly and efficiently. Toloka has a large pool of workers who are available to label data 24/7. The platform helps in getiing human input at all stages of LLM development: Pre-training, fine-tuning and RLHF.
LabelBox
LabelBox is a cloud-based platform for labelling data for machine learning models. LabelBox is particularly well-suited for LLMOps, as it provides a variety of tools and features for labelling data, including a web-based interface, a mobile app, and a REST API. LabelBox's web-based interface is easy to use and can be accessed from any device. The mobile app allows you to label data on the go. The REST API allows you to integrate LabelBox with your existing workflows.
Argilla
Argilla is a platform for managing and deploying machine learning models. Argilla is particularly well-suited for LLMOps, as it provides an open-source data curation platform for LLMs using human and machine feedback loops. Argilla also has a variety of features for managing models, including versioning, experiment tracking, and production deployment. Argilla's versioning system allows you to track changes to your models over time. The experiment tracking system allows you to record the hyperparameters and results of your experiments. The production deployment system allows you to deploy your models to production environments.
Surge
Surge is a platform for deploying machine learning models to production. Surge has a dedicated RLHF platform with key features such as Domain expert labellers, Rapid experimentation interface, RLHF and Language Model expertise. Surge serves a wide range of use cases such as Search Evaluation and Content Moderation. Surge is particularly well-suited for LLMOps, as it provides various features for deploying models to production, including autoscaling, monitoring, and alerting. Surge's autoscaling feature allows you to automatically scale your models up or down based on demand. The monitoring feature allows you to track the performance of your models in production. The alerting feature allows you to be notified when there are problems with your models.
Scale
Scale is a full-stack platform that powers Generative AI strategy—including fine-tuning, prompt engineering, security, model safety, model evaluation, and enterprise apps. It also provides support for RLHF, data generation, safety, and alignment. Scale is particularly well-suited for LLMOps, as it provides a variety of features for managing models at scale, including autoscaling, load balancing, and fault tolerance. Scale's autoscaling feature allows you to automatically scale your models up or down based on demand. The load balancing feature distributes traffic across your models to ensure that they are not overloaded. The fault tolerance feature allows your models to continue operating even if some of them fail.
Model Development: Architectural selection, experiment tracking, fine-tuning, and hyperparameter tuning
Databricks
Databricks recently released their Open Instruction-Tuned LLM, Dolly. Databricks MLFlow is particularly well-suited for LLMOps, as it can be used to track the performance of LLMs over time and to deploy them to production environments. It provides a centralised repository for storing ML experiments, models, and artefacts. Databricks MLFlow also provides a variety of features for tracking the performance of ML models, including experiment tracking, model versioning, and artefact management.
Here are some of the key features of Databricks MLFlow:
- Centralized repository for storing ML experiments, models, and artefacts
- Experiment tracking
- Model versioning
- Artefact management
- Integration with a variety of ML frameworks
- Scalable and reliable
Weights & Biases
A suite of LLMOps tools within the developer-first W&B MLOps platform. Utilize W&B Prompts for visualizing and inspecting LLM execution flow, tracking inputs and outputs, viewing intermediate results, and securely managing prompts and LLM chain configurations.W&B also allows you to share your experiments with other teams, which can be helpful for collaboration and knowledge sharing. W&B is particularly well-suited for LLMOps, as it can be used to track the performance of LLMs over time and to share them with other teams.
Here are some of the key features of W&B:
- Experiment tracking
- Model versioning
- Artefact management
- Sharing of experiments
- Integration with a variety of ML frameworks
- Visual analytics
TrueLens
TrueLens is a platform for managing and deploying large language models (LLMs). TrueLens provides a variety of features for managing LLMs, including versioning, experiment tracking, and production deployment. TrueLens uses feedback functions to measure the quality and effectiveness of your LLM application. TrueLens also allows you to deploy LLMs to a variety of cloud providers, which can be helpful for scalability and reliability. TrueLens is particularly well-suited for teams that are using a variety of ML frameworks, as it can be used to manage models from different frameworks.
Here are some of the key features of TrueLens:
- Managing LLMs
- Versioning
- Experiment tracking
- Production deployment
- Deployment to a variety of cloud providers
- Integration with a variety of ML frameworks
- Scalable and reliable
MosaicML
MosaicML allows you to execute open-source, commercially-licensed models. Easily integrate LLMs into your applications. Also, allows you to deploy out-of-the-box or fine-tune models on your data. Mosaic ML is a platform for building, deploying, and managing machine learning models at scale. Mosaic ML provides a variety of features for managing models at scale, including autoscaling, load balancing, and fault tolerance. Mosaic ML also allows you to monitor the performance of your models in production, which can help you to identify and resolve problems quickly.
Here are some of the key features of Mosaic ML:
- Building and deploying ML models at scale
- Autoscaling
- Load balancing
- Fault tolerance
- Monitoring of model performance
- Integration with a variety of ML frameworks
- Scalable and reliable
Model Deployment and Operations: Strategies for deployment, monitoring, and maintenance.
TrueFoundry
Deploy LLMOps tools like Vector DBs, Embedding server etc on your own Kubernetes (EKS, AKS, GKE, On-prem) Infra including deploying, Fine-tuning, tracking Prompts and serving Open Source LLM Models with full Data Security and Optimal GPU Management. Train and Launch your LLM Application at a production scale with the best Software Engineering practices. TrurFoundry provides 5x faster fine-tuning and 10x faster deployments for LLM models. TrueFounry also has a focus on reducing costs (50% lower) and data security for your Large Language Model Operations.
Run:AI
Run:AI is a platform for end-to-end LLM lifecycle management, enabling enterprises to fine-tune, prompt engineer, and deploy LLM models with ease. It is particularly well-suited for large-scale deployments, as it can scale to handle any amount of traffic. Run:AI's speciality is its ability to automate the entire ML lifecycle, from data preparation to model deployment and monitoring. This can save time and effort, and it can help to ensure that machine learning projects are completed on time and within budget
ZenML
ZenML is a platform for building, managing, and deploying LLMs. It is particularly well-suited for teams that want to automate their LLMOps workflows. ZenML's speciality is its ease of use. It provides a drag-and-drop interface and a library of pre-built components, so teams can quickly and easily build and deploy ML pipelines.
Iguazio
Iguazio enables the key aspects of LLMOps: automating the flow, processing at scale, rolling upgrades, rapid pipeline development and deployment, and model monitoring. Although, some of the steps need to be adapted. For example, the embeddings, tokenization, and data cleansing steps need to be adjusted, to name a few. It is particularly well-suited for teams that need to deploy ML applications across multiple clouds. Iguazio's speciality is its ability to scale ML applications to handle any amount of traffic. It also provides a single platform for managing all of a team's ML deployments, which can save time and effort.
Anyscale
Anyscale’s Aviary is a fully open-source, free, cloud-based LLM-serving infrastructure designed to help developers choose and deploy the right technologies and approach for their LLM-based applications. Anyscals’s Aviary makes it easy to continually assess how multiple LLMs perform against your data and to select and deploy the right one for your apps. Anyscale's speciality is its managed Kubernetes service. This makes it easy to scale ML workloads and ensures that they are always available.
Monitoring, Prompt Engineering and Testing
Arize
Arize is an LLMOps platform that helps teams build, deploy, and manage LLMs for a variety of tasks, including natural language understanding, natural language generation, and question answering. It provides a variety of features for managing LLMs, including version control, experiment tracking, and production deployment. Arize's speciality is its ability to integrate with a variety of other machine learning platforms, so teams can use their existing infrastructure. It also provides a variety of features for monitoring LLMs, so teams can ensure that they are performing as expected.
Comet
Comet’s LLMOps tools are designed to allow users to leverage the latest advancement in Prompt Management and query models in Comet to iterate quicker, identify performance bottlenecks, and visualize the internal state of the Prompt Chains. Comet also provides integrations with Leading Large Language Models and Libraries such as LangChain and OpenAI’s Python SDK. Comet's speciality is its ability to track experiments across multiple machine-learning platforms. It also provides a variety of features for managing machine learning projects, so teams can keep track of their progress and collaborate effectively.
PromptLayer
PromptLayer is a platform for building and deploying large language models (LLMs) as APIs. It provides a variety of features for building LLMs, including a library of pre-built components and a drag-and-drop interface. PromptLayer's speciality is its ability to deploy LLMs as APIs. This makes it easy to use LLMs in a variety of applications, such as chatbots and question-answering systems.
OpenPrompt
OpenPrompt is an open-source framework for building and deploying large language models (LLMs). It provides a variety of features for building LLMs, including a library of pre-built components and a command-line interface. OpenPrompt's speciality is its open-source nature. This makes it easy for teams to customize OpenPrompt to their specific needs.
Orquestra
Orquesta is a platform for orchestrating machine learning pipelines. It provides a variety of features for orchestrating pipelines, including a drag-and-drop interface and a library of pre-built components. Orquesta's speciality is its ability to orchestrate pipelines across multiple machine-learning platforms. This makes it easy to deploy machine learning pipelines to production.
Vector Search and Databases
Pinecone
Pinceone is a vector search engine that is designed for large language models (LLMs). It can be used to search for LLMs by their vector representations, which makes it easy to find the LLM that is most similar to a given query. Pinceone's speciality is its ability to search for LLMs by their vector representations. For example, if you are interested in using the GPT-3 language model, you could use Pinceone to search for LLMs that are similar to GPT-3. Pinceone would then return a list of LLMs that have similar vector representations to GPT-3. This would allow you to easily find the LLM that is most suited to your needs.
Zilliz
Zilliz is a vector database that is designed for LLMs. It can be used to store and query LLMs, as well as to track the performance of LLMs over time. Zilliz's speciality is its ability to store and query LLMs efficiently. Zilliz is a good choice for storing and querying LLMs because it is designed to be efficient with large amounts of data. This means that you can store and query LLMs in Zilliz without having to worry about performance issues.
Milvus
Milvus is a vector database that is designed for large-scale machine-learning applications. It can be used to store and query vectors, as well as to perform similarity searches. Milvus's speciality is its ability to perform similarity searches efficiently. Milvus is a good choice for performing similarity searches on large datasets because it is designed to be efficient with large amounts of data. This means that you can perform similarity searches on large datasets in Milvus without having to worry about performance issues.
Elastic
Elastic is a search engine that is designed for a variety of applications, including vector search. It can be used to search for vectors by their vector representations, as well as to perform a similarity search. Elastic's speciality is its flexibility and scalability. Elastic is a good choice for vector search because it is flexible and scalable. This means that you can use Elastic for a variety of vector search applications, and you can scale Elastic to meet your needs.
Vespa AI
Vespa AI is a search engine that is designed for large-scale machine learning applications. It can be used to store and query vectors, as well as to perform similarity search. Vespa AI's speciality is its ability to perform similarity search efficiently at scale. Vespa AI is a good choice for large-scale similarity search because it is designed to be efficient with large amounts of data. This means that you can perform similarity search on large datasets in Vespa AI without having to worry about performance issues.
Seachium AI
Searchium AI is a search engine that is designed for natural language processing applications. It can be used to search for text documents, as well as to perform similarity search on text. Searchium AI's speciality is its ability to perform similarity search on text documents. Searchium AI is a good choice for natural language processing applications because it is designed to be efficient with text data. This means that you can perform similarity search on text documents in Searchium AI without having to worry about performance issues.
Chroma
Chroma is a vector search engine that is designed for natural language processing applications. It can be used to search for text documents, as well as to perform similarity search on text. Chroma's speciality is its ability to perform similarity search on text documents in real time. Chroma is a good choice for real-time similarity search because it is designed to be efficient with text data. This means that you can perform similarity search on text documents in Chroma without having to worry about performance issues.
Vearch
Vearch is a vector database that is designed for natural language processing applications. It can be used to store and query text documents, as well as to perform similarity search on text. Vearch's speciality is its ability to store and query text documents efficiently. Vearch is a good choice for storing and querying text documents because it is designed to be efficient with text data. This means that you can store and query text documents in Vearch without having to worry about performance issues.
Qdrant
Qdrant is a vector database that is designed for large-scale machine-learning applications. It can be used to store and query vectors, as well as to perform similarity searches. Qdrant's speciality is its ability to perform similarity search efficiently at scale and its support for distributed computing. Qdrant is a good choice for large-scale similarity search and distributed computing because it is designed to be efficient with large amounts of data and to support distributed computing. This means that you can perform similarity search on large datasets in Qdrant without having to worry about performance issues,
Future Trends in LLMOps
Privacy-Preserving Techniques: Focus on protecting data privacy and adopting federated learning
As Large Language Models become more prevalent in various applications, ensuring data privacy has become a significant concern. Future trends in LLMOps will emphasize the adoption of privacy-preserving techniques to safeguard sensitive data. Federated learning is one such approach gaining traction, where models are trained directly on users' devices, and only aggregated model updates are shared with the central server. This way, LLMOps can mitigate privacy risks and build more trustworthy models without compromising user data.
Model Optimization and Compression: Advancements to reduce resource requirements
The resource-intensive nature of Large Language Models demands continuous efforts to optimize and compress these models. Future LLMOps will focus on developing more efficient architectures and algorithms that maintain high performance while reducing memory and computational requirements. Techniques like quantization, distillation, and pruning will play a crucial role in creating lightweight yet powerful LLMs that are more deployable and scalable across various devices and platforms.
Open-Source Contributions: Collaboration and advancements in LLMOps tools and libraries
Open-source contributions will continue to drive innovation and collaboration within the LLMOps community. As LLMs become an essential part of the AI landscape, researchers, developers, and practitioners will actively contribute to LLMOps tools, libraries, and frameworks. This collaborative effort will accelerate LLMOps practices, improve model fine-tuning, and foster the development of cutting-edge applications.
Interpretability and Explainability: Ensuring transparency in model decision-making
With the increasing adoption of LLMs in critical applications, the demand for interpretability and explainability rises. Future LLMOps will focus on techniques to make these models more transparent and understandable. Methods like attention visualization, saliency maps, and model-specific explanations will help provide insights into how LLMs arrive at their decisions, enhancing user trust and enabling better model debugging and improvement.
Integration with Other AI Technologies: Expanding LLMOps into broader AI systems
Large Language Models are just one component of complex AI systems. In the future, LLMOps will extend beyond fine-tuning and deployment of individual LLMs to encompass seamless integration with other AI technologies. This integration will facilitate multimodal AI systems, combining vision, speech, and language processing capabilities to create more holistic and powerful AI solutions.
Conclusion
Recap
The evolution of Large Language Models has revolutionized natural language processing and enabled groundbreaking AI applications. However, their effective management requires specialized practices and processes that fall under the umbrella of LLMOps.
LLMOps plays a crucial role in addressing the challenges of developing, deploying, and maintaining LLMs. By adhering to best practices, adopting specialized tools and platforms, and leveraging advanced techniques, LLMOps teams can overcome computational challenges, ensure data quality, and optimize model performance.
Ongoing developments and potential of LLMOps in the future
As the field of AI continues to advance rapidly, LLMOps will remain at the forefront of innovation. Future trends in LLMOps will focus on privacy-preserving techniques, model optimization, and explainability to address ethical concerns and regulatory requirements. Open-source contributions will foster collaboration and knowledge sharing within the LLMOps community, driving the development of more robust tools and frameworks.
Moreover, the integration of Large Language Models with other AI technologies will lead to exciting advancements, enabling multimodal AI systems with transformative capabilities. As LLMOps evolves, it will play a critical role in unlocking the full potential of Large Language Models, making them more accessible, efficient, and responsible in diverse real-world applications.
In conclusion, LLMOps is the backbone of successful Large Language Model management, ensuring their responsible use and unleashing their power in shaping the future of AI. As AI continues to progress, LLMOps will pave the way for more efficient, trustworthy, and transformative language-based AI applications.
Chat with us
TrueFoundry is an ML Deployment PaaS over Kubernetes that enables ML teams to deploy and monitor models in 15 minutes with 100% reliability, scalability, and the ability to roll back in seconds. In case you are trying to make use of MLOps in your organization, we would love to chat and exchange notes.