Machine Learning Platform Integrations #1: Weights & Biases

Experimentation tracking is a critical aspect of machine learning development, enabling practitioners to manage and track the progress of their experiments efficiently. Experimentation tracking involves recording and monitoring various factors, such as model performance, hyperparameters, and training data, to gain insights into the performance of the machine learning model.
Challenges Faced in managing experiments
Managing experiments and tracking results can be a challenging task for machine learning practitioners due to the complexity of the models, the large amounts of data involved, and the variety of tools and frameworks used in machine learning development. Here are some of the key challenges faced by practitioners in managing experiments and tracking results:
- Reproducibility: Reproducing experiments is essential for verifying results and ensuring that models perform well in real-world scenarios. However, reproducing experiments can be challenging, especially when dealing with complex models, multiple frameworks, and different computing environments.
- Scalability: Machine learning practitioners often work with large datasets, and as such, training models can be a time-consuming process that requires a significant amount of computing power. Managing experiments and tracking results at scale requires tools and infrastructure that can handle large amounts of data and computations.
- Collaboration: Collaboration is essential in machine learning development, but managing experiments and tracking results across multiple team members can be challenging. It requires a robust infrastructure for sharing data, code, and experiment results and ensuring that everyone has access to the same resources.
- Data Management: Machine learning models rely heavily on data, and managing data effectively is critical to the success of the model. However, managing data involves various challenges, such as data cleaning, data labeling, and data versioning, which can be time-consuming and complex.
- Hyperparameter Optimization: Finding the best hyperparameters for a model can be a challenging and iterative process that involves running multiple experiments with different hyperparameters. Managing these experiments and tracking the results can be time-consuming and complex.
Weights & Biases (W&B) and its Features
Weights & Biases (W&B) is a platform designed to help machine learning practitioners manage and track their experiments effectively. It provides a suite of tools for experiment tracking, visualization, and collaboration, making it easier for practitioners to develop robust and scalable machine learning models.
The main features and benefits of the W&B platform are:
- Experiment Tracking: W&B allows users to track their experiments by automatically logging model hyperparameters, metrics, and output artifacts. This allows practitioners to keep track of their experiments and compare different models and hyperparameters easily.
- Visualizations: W&B provides a suite of visualization tools that allow users to visualize their experiments and results. These include 3D visualizations, confusion matrices, and scatter plots, among others. This helps practitioners to better understand their data and identify patterns and trends in experiment results.
- Collaboration: W&B makes it easy to collaborate with team members by providing features for sharing experiments, data, and results. It also provides version control for code and data, ensuring that everyone is working with the same resources.
- Integration: W&B can be easily integrated with a wide range of machine learning frameworks, including TensorFlow, PyTorch, Keras, and Scikit-learn. This allows practitioners to use W&B with their existing workflows and frameworks, without requiring any significant changes to their development process.
- Organization: W&B provides features for organizing experiments, such as projects, runs, and tags. This makes it easy to manage and track experiments across multiple team members and projects.
Setting up Weights & Biases
Setting up W&B for tracking experiments involves several steps:
- Sign up for a W&B account: The first step is to sign up for a free account on the W&B website. This can be done by visiting the website and following the sign-up process.
- Install the W&B library: After signing up for an account, the next step is to install the W&B library in the development environment. The W&B library can be installed using pip or conda, depending on the user's preference and development environment.
- Initialize W&B: Once the library is installed, the user needs to initialize W&B in the code by calling the
wandb.init()function. This function initializes the W&B library and sets up a new run. - Log metrics: The user can log metrics such as loss and accuracy during training by calling the
wandb.log()function. This function takes a dictionary of metrics as input and logs them to the W&B dashboard. - Log hyperparameters: The user can also log hyperparameters such as learning rate and batch size by calling the
wandb.configfunction. This function takes a dictionary of hyperparameters as input and logs them to the W&B dashboard. - Log visualizations: Finally, the user can log visualizations such as images and plots by calling the
wandb.log()function with the appropriate visualization data. W&B provides a wide range of visualization tools, including 3D visualizations, confusion matrices, and scatter plots, among others.
Example:
Here's an example of how to log metrics, models, hyperparameters, and visualizations using W&B:
import wandb
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
# Step 1: Initialize W&B
wandb.init(project="my-project")
# Step 2: Log hyperparameters
config = {
"learning_rate": 0.001,
"batch_size": 32,
"epochs": 10
}
wandb.config.update(config)
# Step 3: Train model and log metrics
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, activation='relu', input_shape=(10,)),
tf.keras.layers.Dense(1)
])
model.compile(optimizer=tf.keras.optimizers.Adam(config['learning_rate']),
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.MeanAbsoluteError()])
for epoch in range(config['epochs']):
# ... train model ...
history = model.fit(x_train, y_train, batch_size=config['batch_size'])
loss = history.history['loss'][-1]
mae = history.history['mean_absolute_error'][-1]
wandb.log({"epoch": epoch, "loss": loss, "mae": mae})
# Step 4: Log visualizations and model
x = np.linspace(0, 10, 100)
y = np.sin(x)
fig, ax = plt.subplots()
ax.plot(x, y)
wandb.log({"my_plot": wandb.Image(fig)})
wandb.save('my_model.h5')
# Step 5: Finish run
wandb.finish()How TrueFoundry Integrates with Weights & Biases
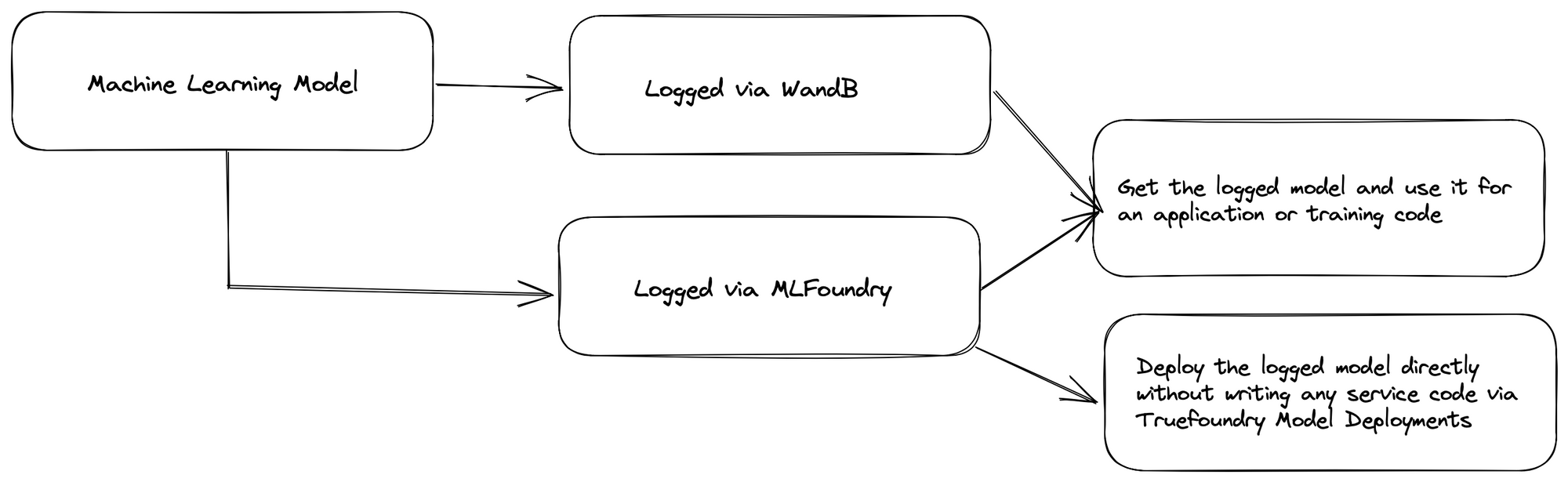
TrueFoundry integrates seamlessly with Weights & Biases Model Registry to allow you to deploy models logged in Weights & Biases to your Kubernetes Cluster using TrueFoundry.
Colab Notebook
Step 1 - Install and setup:
- Install wandb
pip install wandb -qU- Log in to your W&B account
import wandb
wandb.login()- Install servicefoundry
pip install -U "servicefoundry"- Log in to Truefoundry
sfy loginStep 2 - Train and log the model:
We will first use wandb.init() to intialize the project
Then we will train our ML model and save it as a joblib file
Then we will save the our joblib file to wandb via wandb.save()
import wandb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
import joblib
# Initialize W&B
wandb.init(project="iris-logistic-regression")
# Load and preprocess the data
X, y = load_iris(as_frame=True, return_X_y=True)
X = X.rename(columns={
"sepal length (cm)": "sepal_length",
"sepal width (cm)": "sepal_width",
"petal length (cm)": "petal_length",
"petal width (cm)": "petal_width",
})
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Initialize the model
clf = LogisticRegression(solver="liblinear")
# Fit the model
clf.fit(X_train, y_train)
# Evaluate the model
preds = clf.predict(X_test)
# Log the model and the evaluation metrics to W&B
joblib.dump(clf, "model.joblib")
wandb.save("model.joblib")
# Finish the run
wandb.finish()Step 3 - Create an inference application and dependecy file:
We will have to create two files to deploy on truefoundry, a app.py file that contains our application code, and a requirements.txt file that contains our dependencies.
.
├── app.py
├── deploy.py
└── requirements.txt
- app.py:
Here you need to pass the following argument in thewandb.restore():<name_of_saved_file>and"username/project/run_id"
Eg:wandb.restore("model.joblib", "adityajha-tfy/iris-logistic-regression/00r5xvyv")
import os
import wandb
import joblib
import pandas as pd
from fastapi import FastAPI
wandb.login(key=os.environ["WANDB_API_KEY"])
# Retrieve the model from W&B
model_joblib = wandb.restore(
'model.joblib',
run_path="adityajha-tfy/iris-logistic-regression/00r5xvyy",
)
model = joblib.load(model_joblib.name)
# Load the model
app = FastAPI(root_path=os.getenv("TFY_SERVICE_ROOT_PATH"))
@app.post("/predict")
def predict(
sepal_length: float, sepal_width: float, petal_length: float, petal_width: float
):
data = dict(
sepal_length=sepal_length,
sepal_width=sepal_width,
petal_length=petal_length,
petal_width=petal_width,
)
prediction = int(model.predict(pd.DataFrame([data]))[0])
return {"prediction": prediction}- requirements.txt:
fastapi
joblib
numpy
pandas
scikit-learn
uvicorn
wandbStep 4 - Use the truefoundry's python sdk and configure the deployment
- deploy.py:
import argparse
import logging
from servicefoundry import Build, PythonBuild, Service, Resources, Port
# Setup the logger
logging.basicConfig(level=logging.INFO)
# Setup the argument parser
parser = argparse.ArgumentParser()
parser.add_argument("--workspace_fqn", required=True, type=str)
parser.add_argument("--wandb_api_key", required=True, type=str)
args = parser.parse_args()
service = Service(
name="fastapi",
image=Build(
build_spec=PythonBuild(
command="uvicorn app:app --port 8000 --host 0.0.0.0",
requirements_path="requirements.txt",
)
),
ports=[
Port(
port=8000,
host="ml-deploy-aditya-ws-8000.demo.truefoundry.com",
)
],
resources=Resources(
cpu_request=0.25,
cpu_limit=0.5,
memory_request=200,
memory_limit=400,
ephemeral_storage_request=200,
ephemeral_storage_limit=400,
),
env={
"WANDB_API_KEY": args.wandb_api_key
}
)
service.deploy(workspace_fqn=args.workspace_fqn)Step 5 - Deploy your Service via Truefoundry
Run the following command and pass in your
- Workspace FQN: that you can find in the dashboard
- Wandb API Key
python deploy.py --workspace_fqn "<Your Workspace FQN>" --wandb_api_key "<Your Wandb API Key>"And voila!!! In the logs you can find your deployed service's dashboard. And then on top right corner you will find your deployed applications endpoint.
TrueFoundry is a ML Deployment PaaS over Kubernetes to speed up developer workflows while allowing them full flexibility in testing and deploying models while ensuring full security and control for the Infra team. Through our platform, we enable Machine learning Teams to deploy and monitor models in 15 minutes with 100% reliability, scalability, and the ability to roll back in seconds - allowing them to save cost and release Models to production faster, enabling real business value realisation.