Mastering MLOps: A Comprehensive Guide to MLOps Platforms and Best Practices for Successful ML Operations

What is MLOps?
MLOps, short for Machine Learning Operations, is a discipline that merges machine learning (ML) development and operations to streamline the deployment of ML models in real-world applications. Its primary goal is to standardize and automate the continuous delivery of high-performing ML systems, ensuring their reliability and scalability.
The landscape of ML has evolved significantly, presenting organizations with new challenges related to managing complex and large-scale ML systems. In the past, businesses dealt with smaller datasets and a limited number of models. However, with ML becoming pervasive across various domains, the demand for skilled data scientists who can develop and deploy scalable ML systems has risen. Additionally, organizations need to align ML models with changing business objectives, bridge communication gaps between technical and business teams, and assess the risks associated with potential ML model failures.
To excel in the realm of MLOps, it is crucial to develop several key skills. One essential skill is the ability to frame ML problems in the context of business objectives. By defining performance metrics, technical requirements, and key performance indicators (KPIs), ML development can be aligned with the overarching goals of the organization. This ensures that the deployed models are monitored effectively, providing actionable insights.
Architecting ML and data solutions tailored to specific business problems is another critical skill in MLOps. This involves searching for relevant and reliable datasets, ensuring compliance with regulations, and designing data pipelines that facilitate model training and optimization in production environments. Leveraging cloud services and architectures can greatly contribute to the development of performant and cost-effective data pipelines.
By embracing MLOps practices, organizations can overcome the challenges associated with developing and deploying ML models at scale. Standardizing processes, automating workflows, and fostering collaboration between different teams involved in ML production can result in efficient, reliable, and scalable ML systems that drive business success.
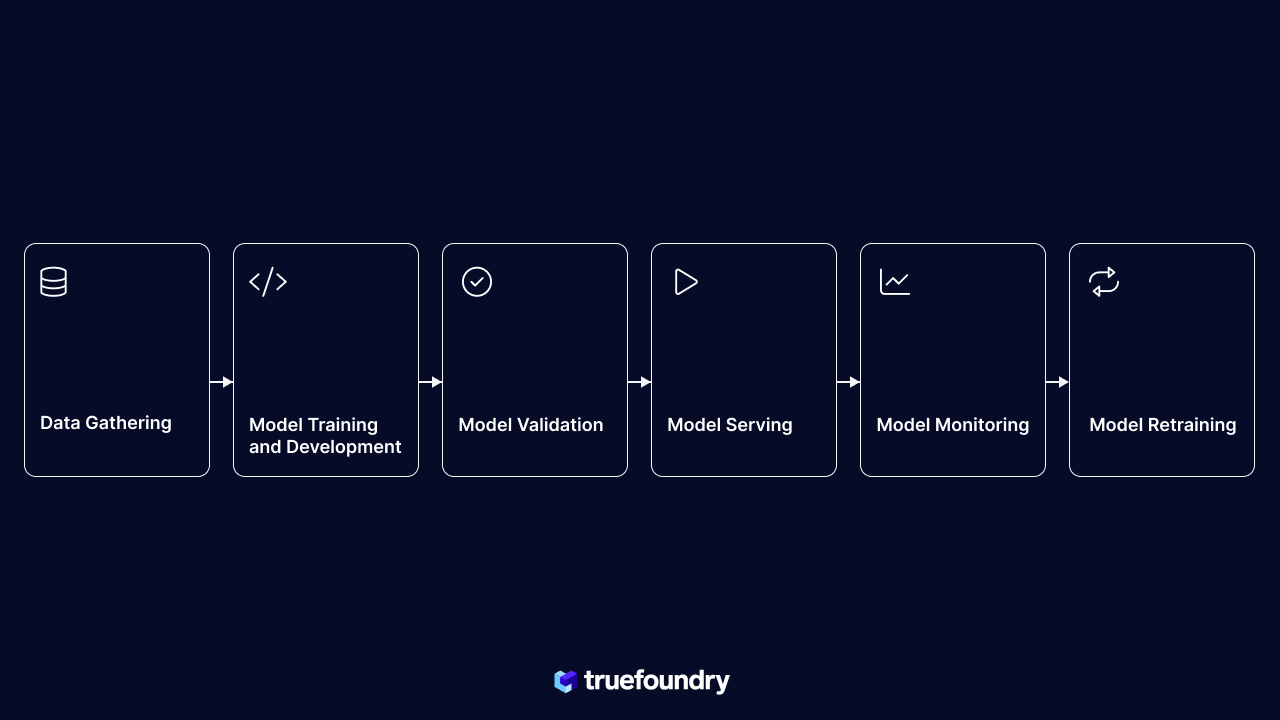
Different Stages of MLOps
In MLOps, several interconnected stages contribute to the development, deployment, and maintenance of ML systems. These stages are:
- Data Gathering, Exploratory Data Analysis, and Data Preparation: These initial stages involve gathering and preparing the data for model building.
- Model Training and Development: Constructing ML models using the prepared datasets, selecting algorithms, defining the model architecture, and optimizing model parameters through training.
- Model Validation: Evaluating the model's performance and generalizability using testing data, assessing metrics like accuracy, precision, and recall, and identifying potential issues like overfitting or underfitting.
- Model Deployment: Deploying the validated model in a production environment, setting up infrastructure, APIs, or applications for real-time or batch predictions, and ensuring scalability, latency, security, and monitoring.
- Model Monitoring: Continuously monitoring deployed ML models by tracking metrics, detecting anomalies, and identifying model drift or degradation to maintain performance and reliability.
- Model Re-training: Periodically updating ML models to adapt to changing data distributions and business requirements, incorporating new data, user feedback, and improving performance.
By understanding and effectively implementing these stages, organizations can develop, deploy, and maintain ML systems that deliver accurate predictions and align with evolving business needs.
Why do we need MLOps?
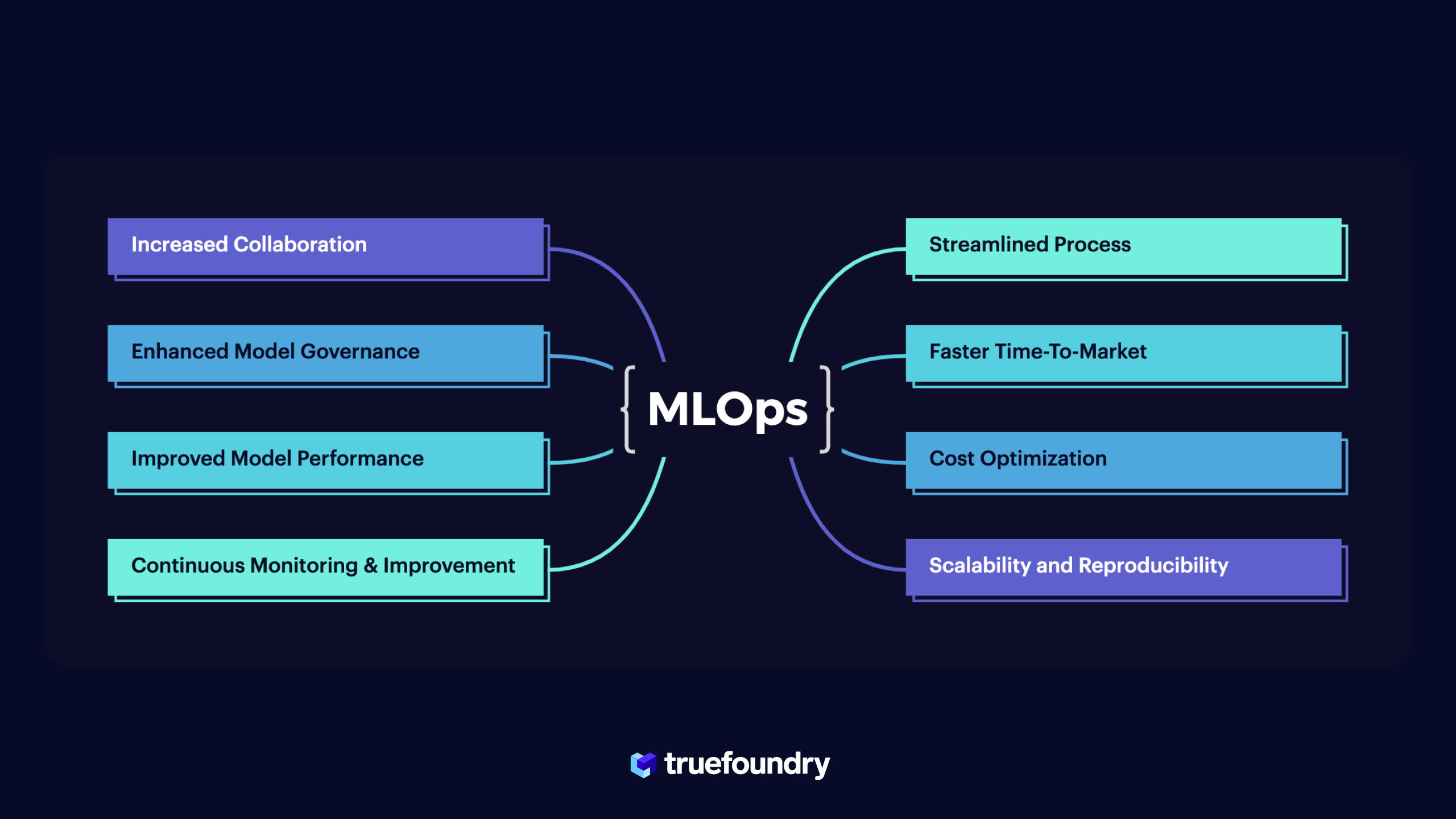
Implementing MLOps, or Machine Learning Operations, offers numerous benefits and advantages for organizations involved in ML production. By streamlining the development, deployment, and maintenance of ML systems, MLOps brings efficiency, scalability, and reliability to the entire ML lifecycle. Let's explore some of the key benefits of adopting MLOps practices:
- Streamlined Process: MLOps provides a structured approach, eliminating ad-hoc processes and establishing guidelines for efficient ML production. It reduces inefficiencies, accelerates development cycles, and improves overall productivity.
- Increased Collaboration: MLOps fosters collaboration between teams involved in ML production, breaking down silos and aligning stakeholders. It promotes cross-functional communication, leading to better decision-making, improved models, and increased business impact.
- Enhanced Model Governance: MLOps incorporates governance practices to ensure compliance, security, and fairness in ML models. It helps organizations meet regulatory requirements, build trust, and maintain transparency throughout the ML lifecycle.
- Scalability and Reproducibility: MLOps enables seamless scaling and reproducibility of ML operations by leveraging cloud infrastructure, containerization, and orchestration tools. It facilitates easy deployment across different environments, ensuring reliable model replication and updates.
- Continuous Monitoring and Improvement: MLOps emphasizes continuous monitoring, enabling real-time anomaly detection, performance tracking, and timely interventions. It ensures ML models remain accurate, reliable, and aligned with business requirements.
- Faster Time-to-Market: MLOps automates tasks, version control, and deployment processes, reducing manual effort and accelerating ML application development. It enables quick iteration, experimentation, and responsiveness to market dynamics.
- Cost Optimization: MLOps optimizes resource utilization by leveraging cloud services and enabling dynamic provisioning of compute resources. It avoids upfront investments, leading to cost savings and improved cost-effectiveness in ML operations.
- Improved Model Performance: MLOps enhances ML model performance through continuous monitoring and addressing issues like performance, data drift, and concept drift. It enables model retraining with new data, ensuring accurate predictions over time.
MLOps Platforms
In the rapidly evolving field of machine learning, MLOps platforms have emerged as crucial tools for organizations seeking to effectively manage and streamline their machine learning operations. These platforms play a vital role in bridging the gap between data scientists, machine learning engineers, and operations teams, enabling collaboration, scalability, and reliability throughout the ML production process. Let's explore the key components and features of MLOps platforms:
- Training
MLOps platforms like TrueFoundry, Weights and Biases, MLflow, Kubeflow, and ClearML Extended streamline and optimize model training. They enable efficient experiment tracking, hyperparameter tuning, and collaboration, ensuring reproducibility and scalability for high-quality model development - Tracking and Versioning
MLOps platforms like ClearML and MLflow enable comprehensive tracking and versioning of datasets, code, and models, ensuring reproducibility, transparency, and collaboration. - Machine Learning Pipelines
Platforms such as Kubeflow and Flyte automate and streamline end-to-end machine learning pipelines, encompassing data ingestion, preprocessing, model training, and deployment, enhancing productivity and enabling efficient collaboration. - Model Deployment
MLOps platforms like TureFoundry, Seldon and Valohai simplify scalable and reliable model deployment, leveraging containerization technologies and ensuring high availability, scalability, and efficient resource utilization. - Monitoring and Governance
Tools like Dataiku and cnvrg.io provide real-time monitoring, tracking performance metrics, detecting anomalies, and enabling comprehensive governance to ensure optimal and compliant operation of ML models.
Internal MLOps Platforms
In addition to their internal ML platforms, several tech giants have significantly contributed to the broader MLOps ecosystem. These companies have developed and open-sourced powerful MLOps platforms that have gained widespread adoption and popularity. These platforms provide robust capabilities to streamline and optimize the end-to-end ML lifecycle. Here are a few notable examples:
- FB Learner: Facebook's ML platform streamlines end-to-end workflows with collaboration, distributed computing, and advanced features for versioning, monitoring, and debugging.
- Google Cloud AI Platform: Google's comprehensive ML platform for building, deploying, and managing models at scale, supporting popular frameworks with AutoML and HyperTune capabilities.
- Uber's Michelangelo: Uber's ML platform provides infrastructure for training and serving models, supporting TensorFlow and PyTorch, with features like data versioning and experiment tracking.
- Netflix's Metaflow: Netflix's ML platform simplifies ML workflows with a Python-based framework, integrating with TensorFlow and PyTorch, offering data versioning and deployment to production.
- Airbnb's Bighead: Airbnb's ML platform democratises ML with a user-friendly interface, supporting data exploration, training, and deployment, powering applications like pricing optimization and search ranking.
- Microsoft's Azure Machine Learning: Microsoft's cloud-based ML platform offers collaborative environments, data preprocessing, model training, automated ML, and deployment, utilized internally and within the Azure ecosystem.

External MLOps PLatforms
Training
- TrueFoundry
An MLOps platform that empowers organizations to build, deploy, and manage machine learning models efficiently, with features like data management, model versioning, and automated pipeline orchestration. - Weights and Biases
A powerful MLOps platform with comprehensive experiment tracking, hyperparameter sweeps, and interactive visualizations, facilitating efficient model development and seamless collaboration among data science teams. - MLflow
A robust platform that simplifies tracking and managing ML experiments, enabling reproducibility and easy model versioning across various machine learning frameworks and libraries. - Kubeflow
A scalable, Kubernetes-based MLOps platform automating end-to-end ML workflows, including data preprocessing, model training, and deployment, with a focus on efficient resource utilization and seamless scalability. - ClearML
A feature-rich platform designed for efficient experiment tracking, model visualization, and collaborative development, enhancing reproducibility and team productivity throughout the machine learning lifecycle.
Tracking and Versioning
- MLflow
An open-source MLOps platform that provides tracking, versioning, and deployment capabilities for machine learning models, enabling easy reproducibility and collaboration across the ML lifecycle. - Weights and Biases
A powerful MLOps platform that enables experiment tracking, model visualization, and collaboration, providing deep insights into model performance and facilitating efficient model development and deployment. - ClearML
A powerful MLOps platform that enables end-to-end management of machine learning experiments, data versioning, and model deployment, with comprehensive tracking and collaboration features. - Neptune
A collaborative MLOps platform with experiment tracking, visualizations, and reproducibility tools, facilitating efficient teamwork and seamless integration with popular machine learning frameworks. - CometML
An MLOps platform designed for experiment tracking, model visualization, and collaboration, providing a centralized hub to manage experiments and collaborate with team members. - DVC
A data versioning and pipeline management tool for MLOps, enabling efficient tracking of data changes, experiment reproducibility, and seamless integration with popular ML frameworks. - Pachyderm
A data versioning and data lineage tracking platform for MLOps, empowering teams to version and track data at scale, facilitating reproducibility and collaboration across the ML workflow.
Machine Learning Pipelines
- Kubeflow
An open-source MLOps platform built on Kubernetes, providing a scalable and portable framework for deploying, managing, and orchestrating machine learning workflows in a distributed environment. - Metaflow
Netflix's Python-based MLOps platform simplifies the development of scalable and reproducible ML pipelines, supporting popular libraries, and offering features like data versioning and deployment. - Airflow
An open-source MLOps platform for workflow orchestration, allowing users to define, schedule, and monitor complex ML pipelines, providing flexibility and scalability for data processing and model deployment. - ZenML
A lightweight and extensible MLOps framework that focuses on reproducibility and pipeline automation, offering a pipeline-centric approach to managing end-to-end machine learning workflows. - Kedro Pipelines
An open-source development workflow framework that enables reproducibility and modularity in MLOps, allowing teams to build scalable and maintainable machine learning pipelines. - Flyte
A cloud-native MLOps platform that offers a scalable and highly customizable workflow engine, enabling teams to build, manage, and monitor complex machine learning workflows with ease. - Prefect
A data engineering and workflow orchestration platform for MLOps, providing tools for building, scheduling, and monitoring data pipelines with robust support for machine learning workflows.
Model Deployment:
- TrueFoundry
An MLOps platform that empowers organizations to build, deploy, and manage machine learning models efficiently, with features like data management, model versioning, and automated pipeline orchestration. - Seldon
An open-source MLOps platform that specializes in deploying and managing machine learning models at scale, with features like model monitoring, A/B testing, and canary deployments. - BentoML
An MLOps framework that simplifies the deployment of machine learning models as REST APIs or Docker containers, providing easy integration with various deployment platforms. - NVIDIA Triton Inference Server
A production-grade inference serving platform from NVIDIA, offering high-performance model deployment and scalability with support for various machine learning frameworks. - OctoML
An MLOps platform that optimizes and deploys machine learning models across different hardware architectures, ensuring high performance and efficient resource utilization. - NVIDIA TensorRT
An inference optimization and deployment framework that accelerates deep learning models on NVIDIA GPUs, delivering high throughput and low latency for production deployments. - Valohai
A collaborative MLOps platform that automates machine learning infrastructure, experiment tracking, and deployment, allowing teams to focus on model development and iteration efficiently. - Cortex
An MLOps platform that simplifies the deployment and management of machine learning models at scale, providing seamless integration with popular frameworks and efficient resource utilization. - AWS SageMaker
A fully managed MLOps platform by Amazon Web Services (AWS), providing tools and infrastructure for building, training, deploying, and managing machine learning models at scale in the cloud. - Iguazio
A unified MLOps platform that enables organizations to develop, deploy, and manage AI applications at scale, leveraging real-time data processing, model deployment, and automated operations on Kubernetes. - Domino Data Labs
Domino is an enterprise-grade MLOps platform that enables teams to collaborate, build, deploy, and manage models at scale, with features like experiment tracking, reproducibility, and model deployment automation.
Monitoring and Governance:
- Dataiku
An all-in-one MLOps platform that facilitates end-to-end machine learning workflows, from data preparation to model deployment, with built-in collaboration, automation, and monitoring capabilities. - cnvrg.io
A collaborative MLOps platform that streamlines the development and deployment of machine learning models, with features like experiment tracking, reproducibility, and scalable infrastructure management. - WhyLabs
An MLOps platform that focuses on model performance monitoring and explainability, providing insights into model behaviour, data drift detection, and alerts for improved model reliability and interoperability. - ArizeAI
A platform for model monitoring and explainability, enabling teams to track model performance, detect anomalies, and explain predictions, ensuring transparency and trust in ML systems. - Superwise
An MLOps platform that automates the monitoring and governance of machine learning models in production, ensuring model health, detecting anomalies, and providing actionable insights for improved reliability. - EvidentlyAI
A tool for ML model monitoring and analysis, providing comprehensive statistical insights, metrics, and visualizations to evaluate model performance, detect anomalies, and ensure ongoing model quality. - Aporia
An MLOps platform specializing in model monitoring and data quality, offering automated detection of data and model issues, and facilitating proactive management of machine learning models in production. - Truera
Truera is an MLOps platform that focuses on model interpretability and explainability, providing insights into model behaviour and helping ensure transparency, fairness, and compliance in ML models.
Our Top Picks
Training
- TrueFoundry
- Weights & Biases
- ClearML
- MLflow
- Kubeflow
Tracking and Versioning
- MLflow
- Weights and Biases
- ClearML
- Neptune
- CometML
Machine Learning Pipelines:
- Kubeflow
- Metaflow
- Airflow
- ZenML
- Kedro Pipelines
Model Deployment:
- TrueFoundry
- AWS SageMaker
- NVIDIA Triton Inference Server
- Seldon
- BentoML
- Cortex
Monitoring and Governance:
- Dataiku
- cnvrg.io
- WhyLabs
- ArizeAI
- Superwise
Chat with us
TrueFoundry is an ML Deployment PaaS over Kubernetes that enables ML teams to deploy and monitor models in 15 minutes with 100% reliability, scalability, and the ability to roll back in seconds. In case you are trying to make use of MLOps in your organization, we would love to chat and exchange notes.